垃圾回收器算法
GC
垃圾回收概述
- 哪些內存需要回收?
- 什么時候回收?
- 如何回收?
大廠面試題
螞蟻金服
百度
天貓
滴滴
京東
阿里
字節跳動
什么是垃圾?
為什么需要GC?
想要學習GC,首先需要理解為什么需要GC?
早期垃圾回收
Java 垃圾回收機制
自動內存管理
官網介紹:https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/toc.html
自動內存管理的優點
關于自動內存管理的擔憂
應該關心哪些區域的回收?
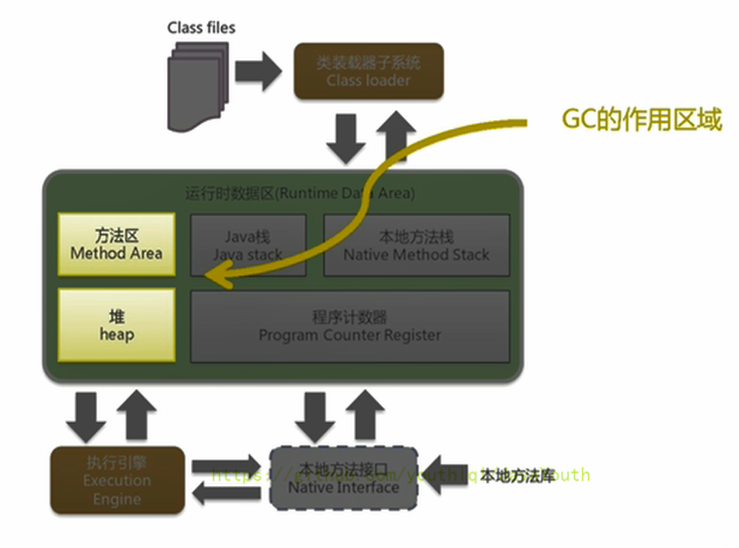
垃圾回收相關算法
標記階段:引用計數算法
標記階段的目的
垃圾標記階段:主要是為了判斷對象是否存活
引用計數算法
循環引用
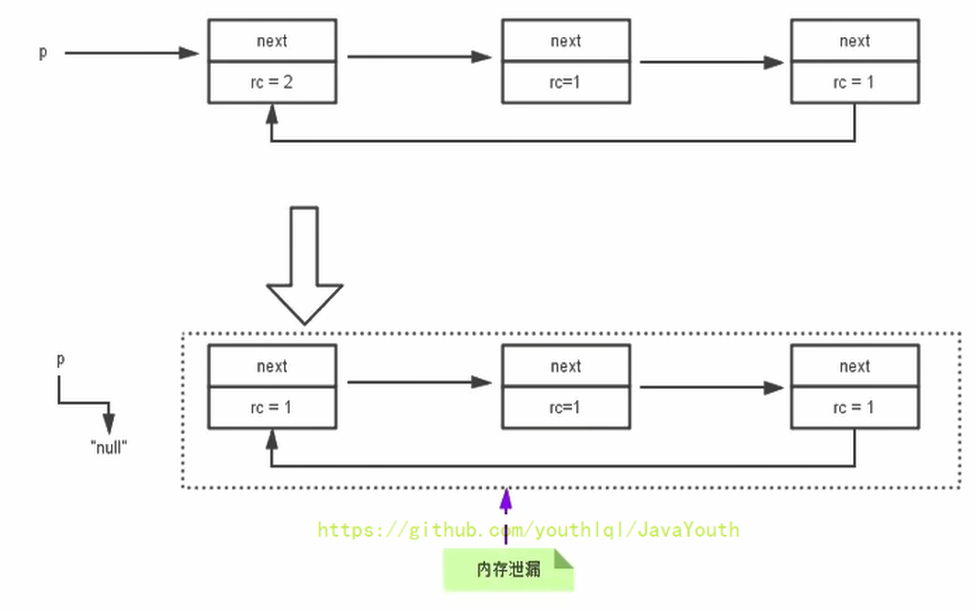
當p的指針斷開的時候,內部的引用形成一個循環,計數器都還算1,無法被回收,這就是循環引用,從而造成內存泄漏
證明:java使用的不是引用計數算法
/*** -XX:+PrintGCDetails* 證明:java使用的不是引用計數算法*/ public class RefCountGC {//這個成員屬性唯一的作用就是占用一點內存private byte[] bigSize = new byte[5 * 1024 * 1024];//5MBObject reference = null;public static void main(String[] args) {RefCountGC obj1 = new RefCountGC();RefCountGC obj2 = new RefCountGC();obj1.reference = obj2;obj2.reference = obj1;obj1 = null;obj2 = null;//顯式的執行垃圾回收行為//這里發生GC,obj1和obj2能否被回收?System.gc();} }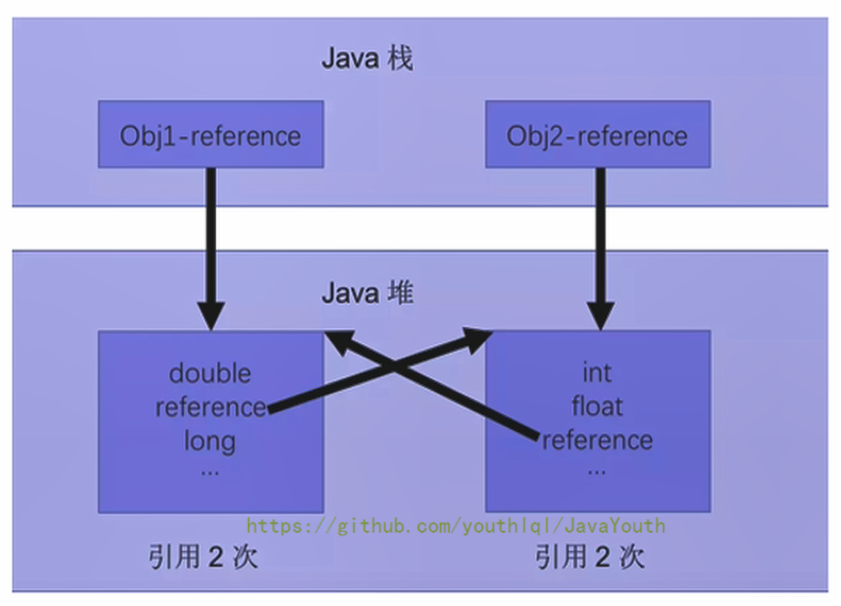
- 如果不小心直接把obj1.reference和obj2.reference置為null。則在Java堆中的兩塊內存依然保持著互相引用,無法被回收
沒有進行GC時
把下面的幾行代碼注釋掉,讓它來不及
System.gc();//把這行代碼注釋掉 HeapPSYoungGen total 38400K, used 14234K [0x00000000d5f80000, 0x00000000d8a00000, 0x0000000100000000)eden space 33280K, 42% used [0x00000000d5f80000,0x00000000d6d66be8,0x00000000d8000000)from space 5120K, 0% used [0x00000000d8500000,0x00000000d8500000,0x00000000d8a00000)to space 5120K, 0% used [0x00000000d8000000,0x00000000d8000000,0x00000000d8500000)ParOldGen total 87552K, used 0K [0x0000000081e00000, 0x0000000087380000, 0x00000000d5f80000)object space 87552K, 0% used [0x0000000081e00000,0x0000000081e00000,0x0000000087380000)Metaspace used 3496K, capacity 4498K, committed 4864K, reserved 1056768Kclass space used 387K, capacity 390K, committed 512K, reserved 1048576KProcess finished with exit code 0進行GC
打開那行代碼的注釋
[GC (System.gc()) [PSYoungGen: 13569K->808K(38400K)] 13569K->816K(125952K), 0.0012717 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] [Full GC (System.gc()) [PSYoungGen: 808K->0K(38400K)] [ParOldGen: 8K->670K(87552K)] 816K->670K(125952K), [Metaspace: 3491K->3491K(1056768K)], 0.0051769 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] HeapPSYoungGen total 38400K, used 333K [0x00000000d5f80000, 0x00000000d8a00000, 0x0000000100000000)eden space 33280K, 1% used [0x00000000d5f80000,0x00000000d5fd34a8,0x00000000d8000000)from space 5120K, 0% used [0x00000000d8000000,0x00000000d8000000,0x00000000d8500000)to space 5120K, 0% used [0x00000000d8500000,0x00000000d8500000,0x00000000d8a00000)ParOldGen total 87552K, used 670K [0x0000000081e00000, 0x0000000087380000, 0x00000000d5f80000)object space 87552K, 0% used [0x0000000081e00000,0x0000000081ea7990,0x0000000087380000)Metaspace used 3498K, capacity 4498K, committed 4864K, reserved 1056768Kclass space used 387K, capacity 390K, committed 512K, reserved 1048576KProcess finished with exit code 01、從打印日志就可以明顯看出來,已經進行了GC
2、如果使用引用計數算法,那么這兩個對象將會無法回收。而現在兩個對象被回收了,說明Java使用的不是引用計數算法來進行標記的。
小結
- 手動解除:很好理解,就是在合適的時機,解除引用關系。
- 使用弱引用weakref,weakref是Python提供的標準庫,旨在解決循環引用。
標記階段:可達性分析算法
可達性分析算法:也可以稱為根搜索算法、追蹤性垃圾收集
可達性分析實現思路
- 所謂"GCRoots”根集合就是一組必須活躍的引用
- 其基本思路如下:
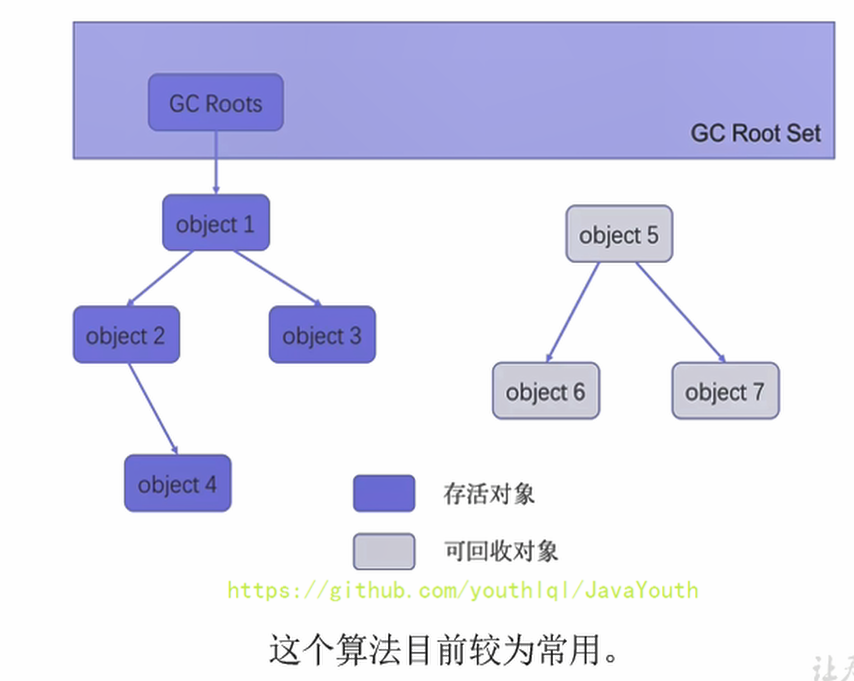
GC Roots可以是哪些元素?
- 比如:各個線程被調用的方法中使用到的參數、局部變量等。
- 比如:Java類的引用類型靜態變量
- 比如:字符串常量池(StringTable)里的引用
- 基本數據類型對應的Class對象,一些常駐的異常對象(如:NullPointerException、OutofMemoryError),系統類加載器。
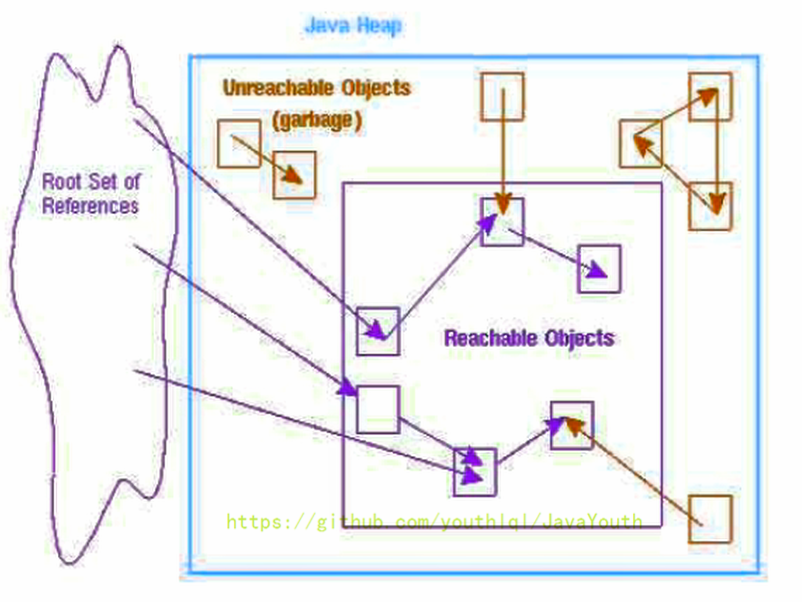
- 如果只針對Java堆中的某一塊區域進行垃圾回收(比如:典型的只針對新生代),必須考慮到內存區域是虛擬機自己的實現細節,更不是孤立封閉的,這個區域的對象完全有可能被其他區域的對象所引用,這時候就需要一并將關聯的區域對象也加入GC Roots集合中去考慮,才能保證可達性分析的準確性。
小技巧
由于Root采用棧方式存放變量和指針,所以如果一個指針,它保存了堆內存里面的對象,但是自己又不存放在堆內存里面,那它就是一個Root。
注意
對象的 finalization 機制
finalize() 方法機制
對象銷毀前的回調函數:finalize()
Object 類中 finalize() 源碼
// 等待被重寫 protected void finalize() throws Throwable { }生存還是死亡?
由于finalize()方法的存在,虛擬機中的對象一般處于三種可能的狀態。
具體過程
判定一個對象objA是否可回收,至少要經歷兩次標記過程:
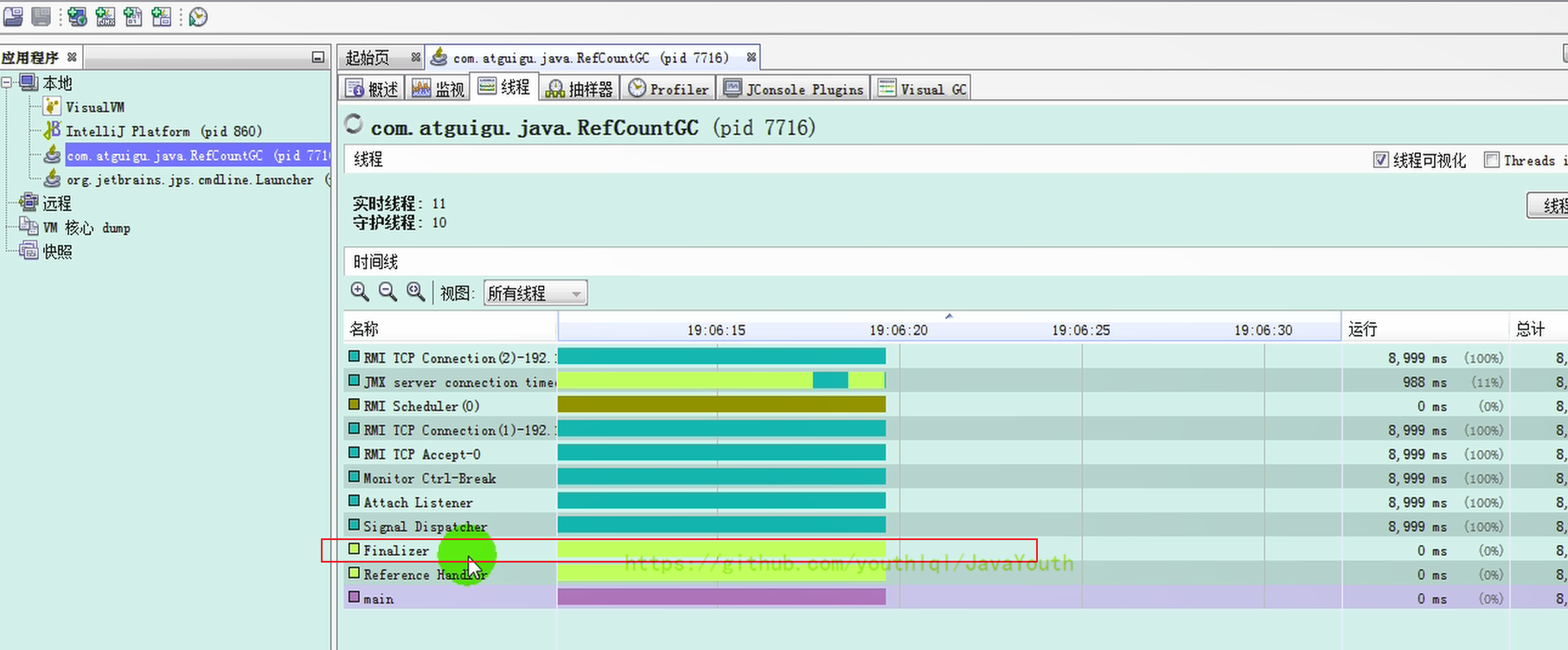
通過 JVisual VM 查看 Finalizer 線程
代碼演示 finalize() 方法可復活對象
我們重寫 CanReliveObj 類的 finalize()方法,在調用其 finalize()方法時,將 obj 指向當前類對象 this
/*** 測試Object類中finalize()方法,即對象的finalization機制。**/ public class CanReliveObj {public static CanReliveObj obj;//類變量,屬于 GC Root//此方法只能被調用一次@Overrideprotected void finalize() throws Throwable {super.finalize();System.out.println("調用當前類重寫的finalize()方法");obj = this;//當前待回收的對象在finalize()方法中與引用鏈上的一個對象obj建立了聯系}public static void main(String[] args) {try {obj = new CanReliveObj();// 對象第一次成功拯救自己obj = null;System.gc();//調用垃圾回收器System.out.println("第1次 gc");// 因為Finalizer線程優先級很低,暫停2秒,以等待它Thread.sleep(2000);if (obj == null) {System.out.println("obj is dead");} else {System.out.println("obj is still alive");}System.out.println("第2次 gc");// 下面這段代碼與上面的完全相同,但是這次自救卻失敗了obj = null;System.gc();// 因為Finalizer線程優先級很低,暫停2秒,以等待它Thread.sleep(2000);if (obj == null) {System.out.println("obj is dead");} else {System.out.println("obj is still alive");}} catch (InterruptedException e) {e.printStackTrace();}} }如果注釋掉finalize()方法
//此方法只能被調用一次@Overrideprotected void finalize() throws Throwable {super.finalize();System.out.println("調用當前類重寫的finalize()方法");obj = this;//當前待回收的對象在finalize()方法中與引用鏈上的一個對象obj建立了聯系}輸出結果:
第1次 gc obj is dead 第2次 gc obj is dead放開finalize()方法
輸出結果:
第1次 gc 調用當前類重寫的finalize()方法 obj is still alive 第2次 gc obj is dead第一次自救成功,但由于 finalize() 方法只會執行一次,所以第二次自救失敗
MAT與JProfiler的GC Roots溯源
MAT 介紹
1、雖然Jvisualvm很強大,但是在內存分析方面,還是MAT更好用一些
2、此小節主要是為了實時分析GC Roots是哪些東西,中間需要用到一個dump的文件
獲取 dump 文件方式
方式一:命令行使用 jmap
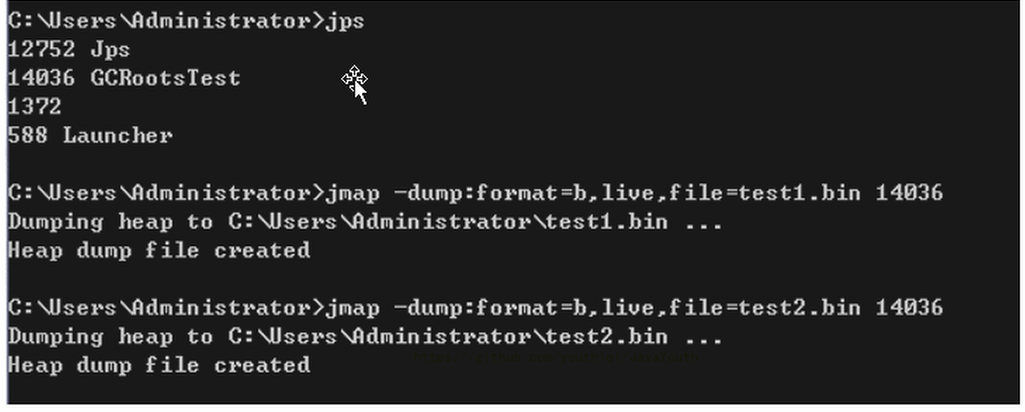
方式二:使用JVisualVM
捕捉 dump 示例
使用JVisualVM捕捉 heap dump
代碼:
- numList 和 birth 在第一次捕捉內存快照的時候,為 GC Roots
- 之后 numList 和 birth 置為 null ,對應的引用對象被回收,在第二次捕捉內存快照的時候,就不再是 GC Roots
如何捕捉堆內存快照
1、先執行第一步,然后停下來,去生成此步驟dump文件
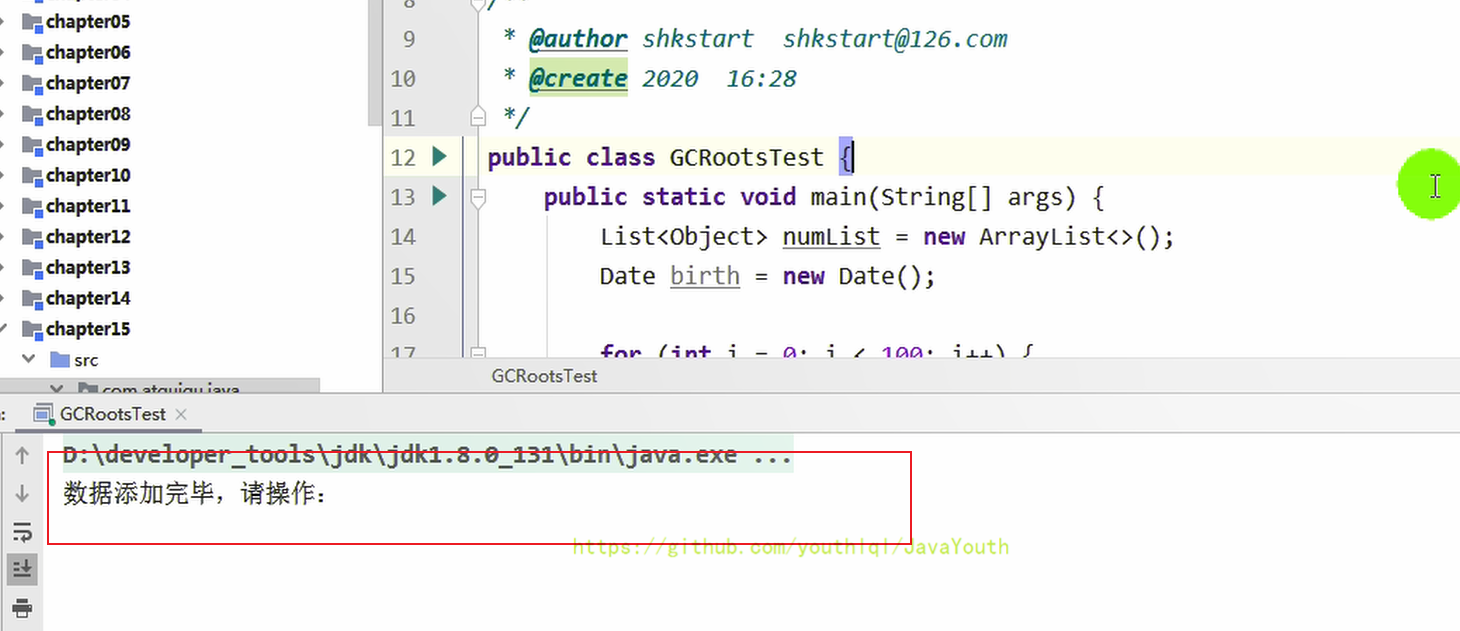
2、 點擊【堆 Dump】
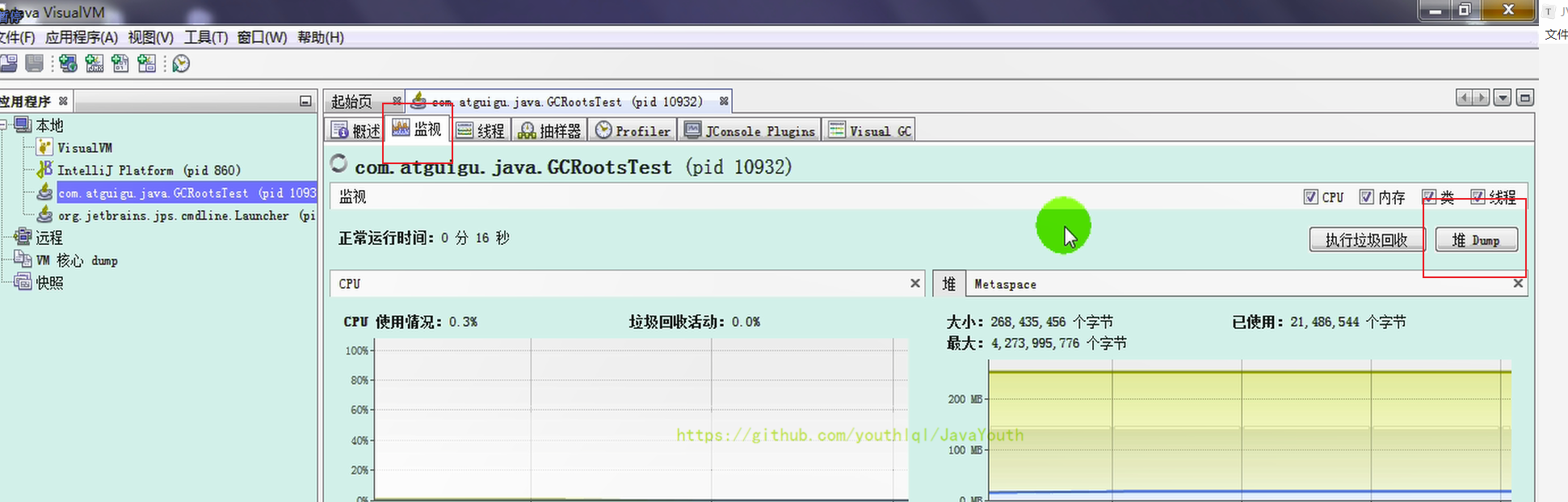
3、右鍵 --> 另存為即可
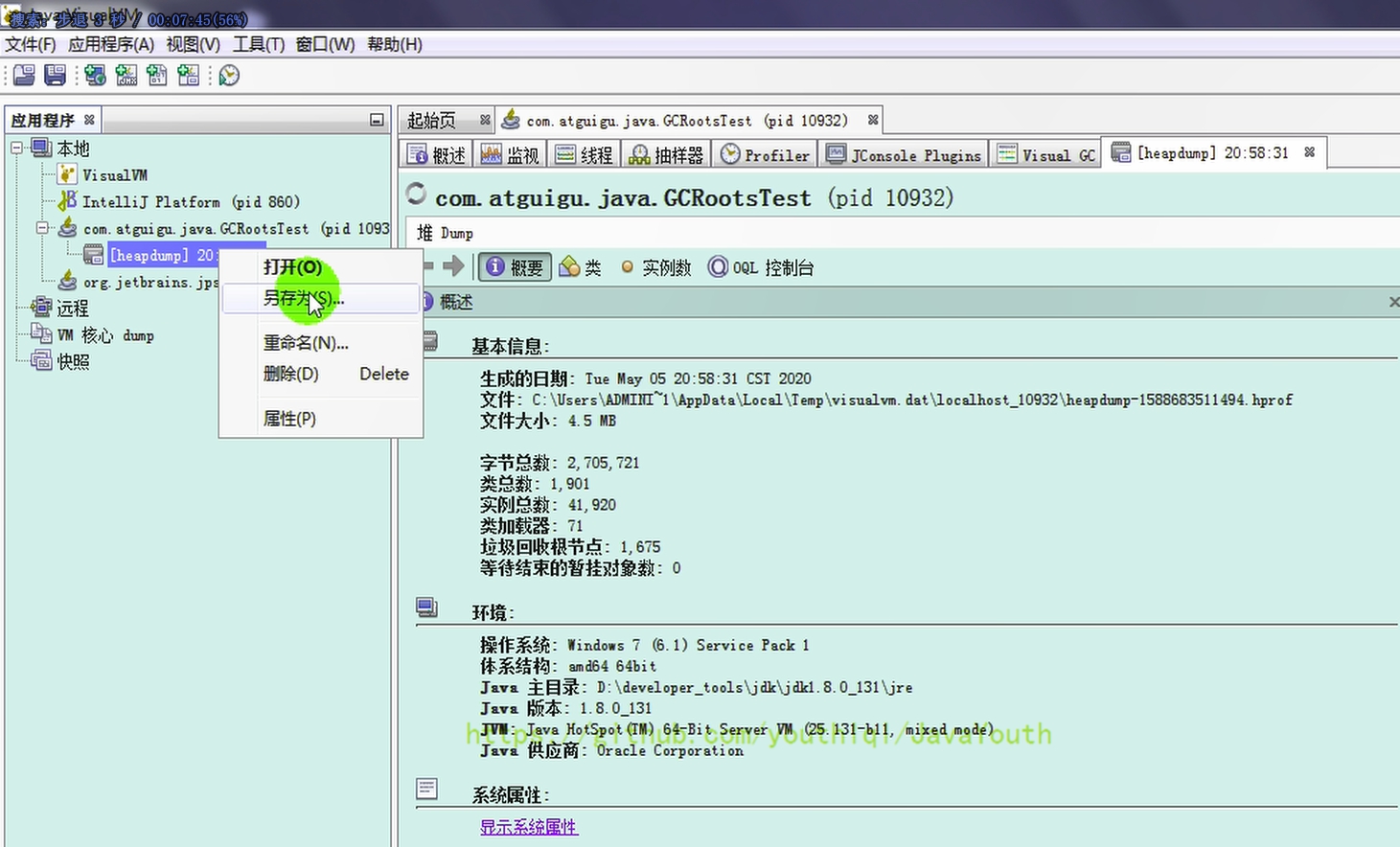
4、輸入命令,繼續執行程序
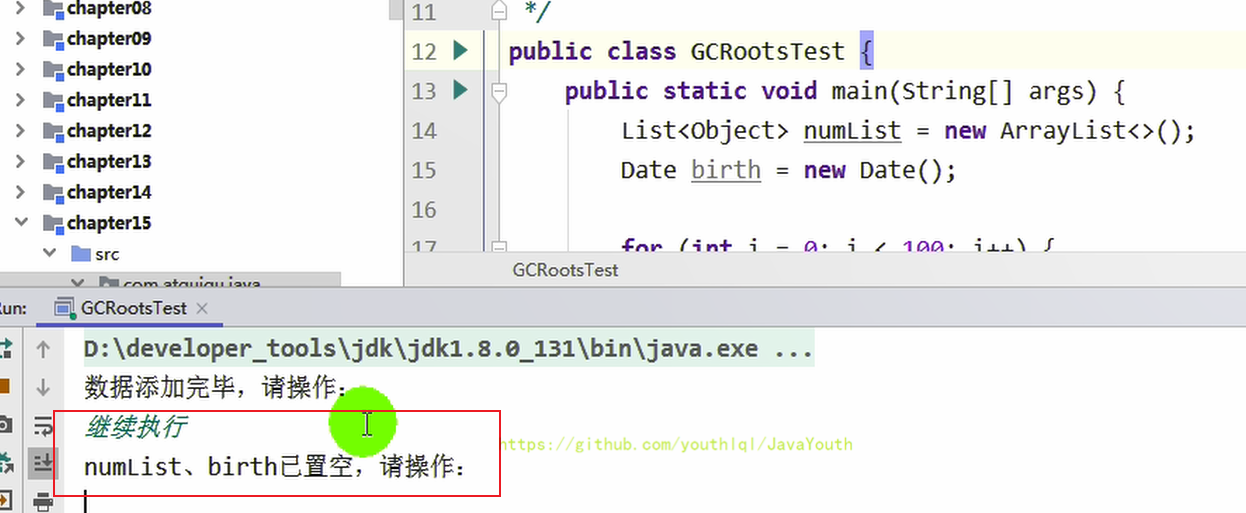
5、我們接著捕獲第二張堆內存快照
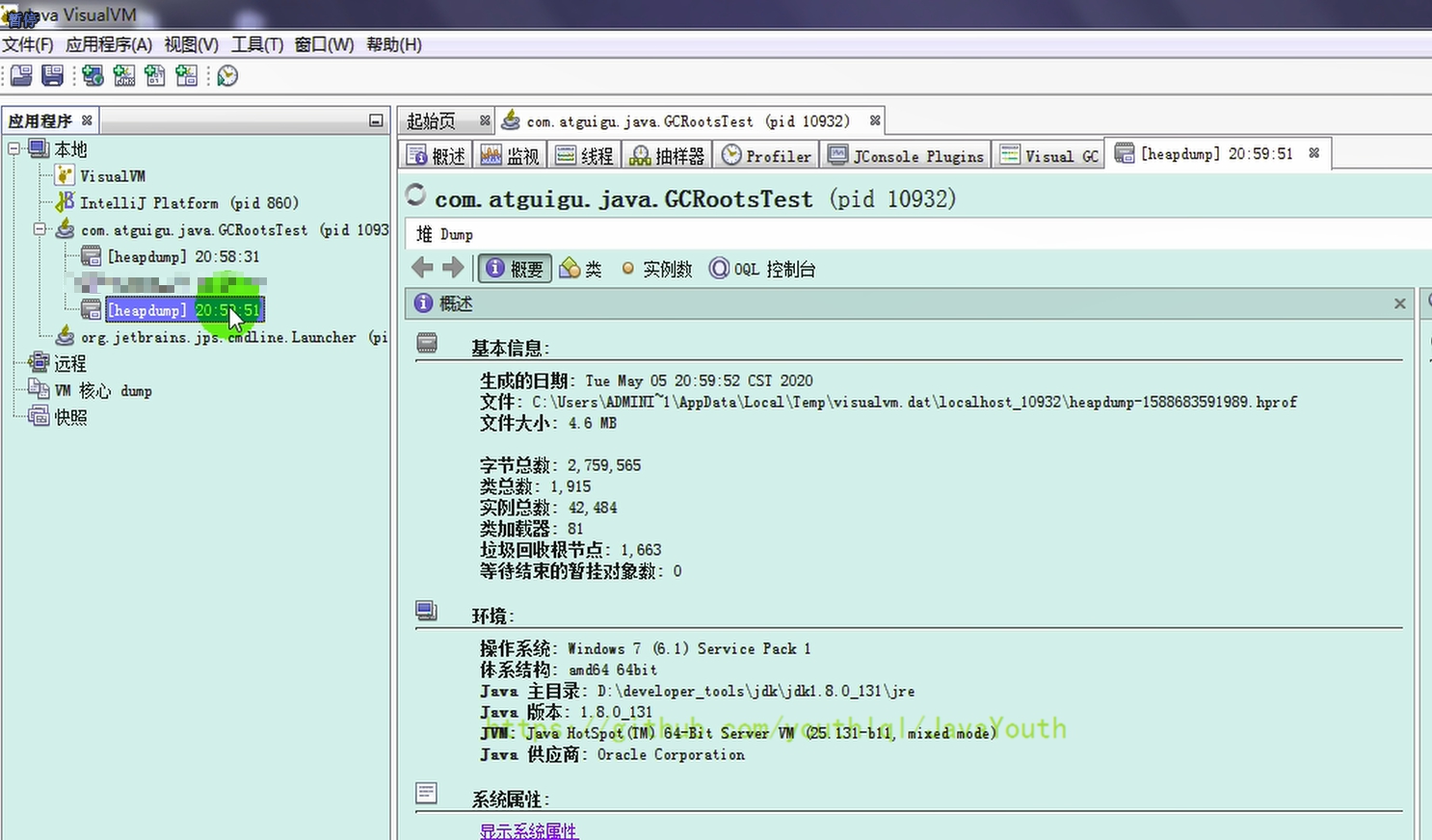
使用 MAT 查看堆內存快照
1、打開 MAT ,選擇File --> Open File,打開剛剛的兩個dump文件,我們先打開第一個dump文件
點擊Open Heap Dump也行
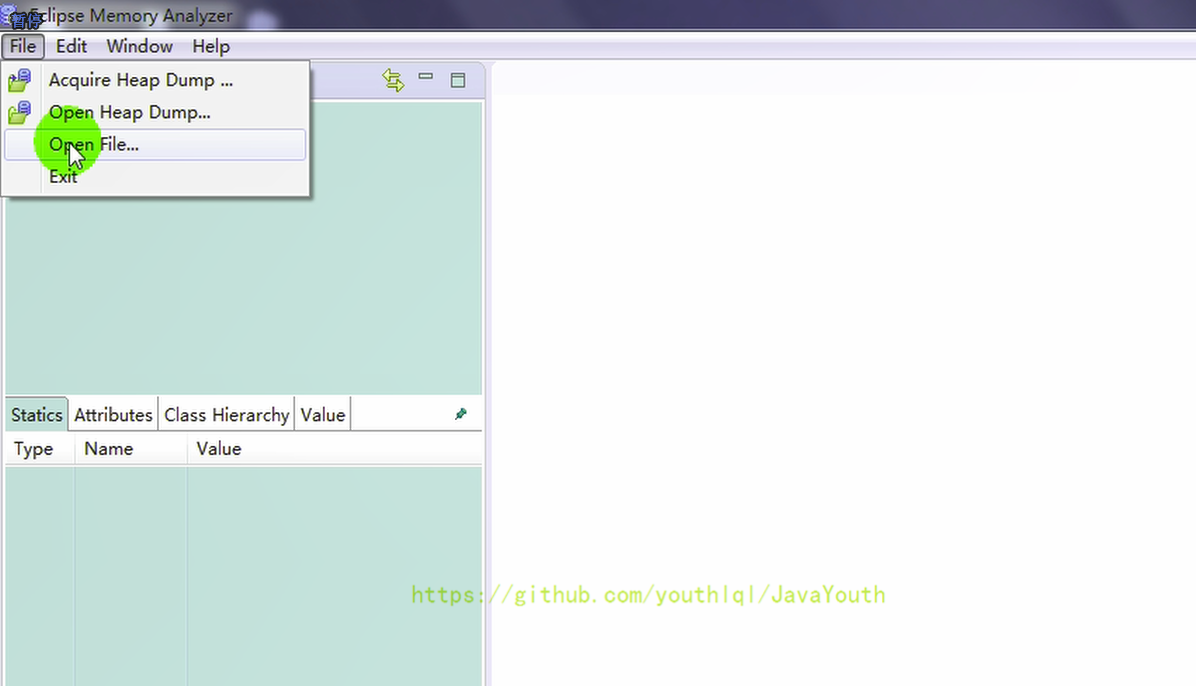
2、選擇Java Basics --> GC Roots
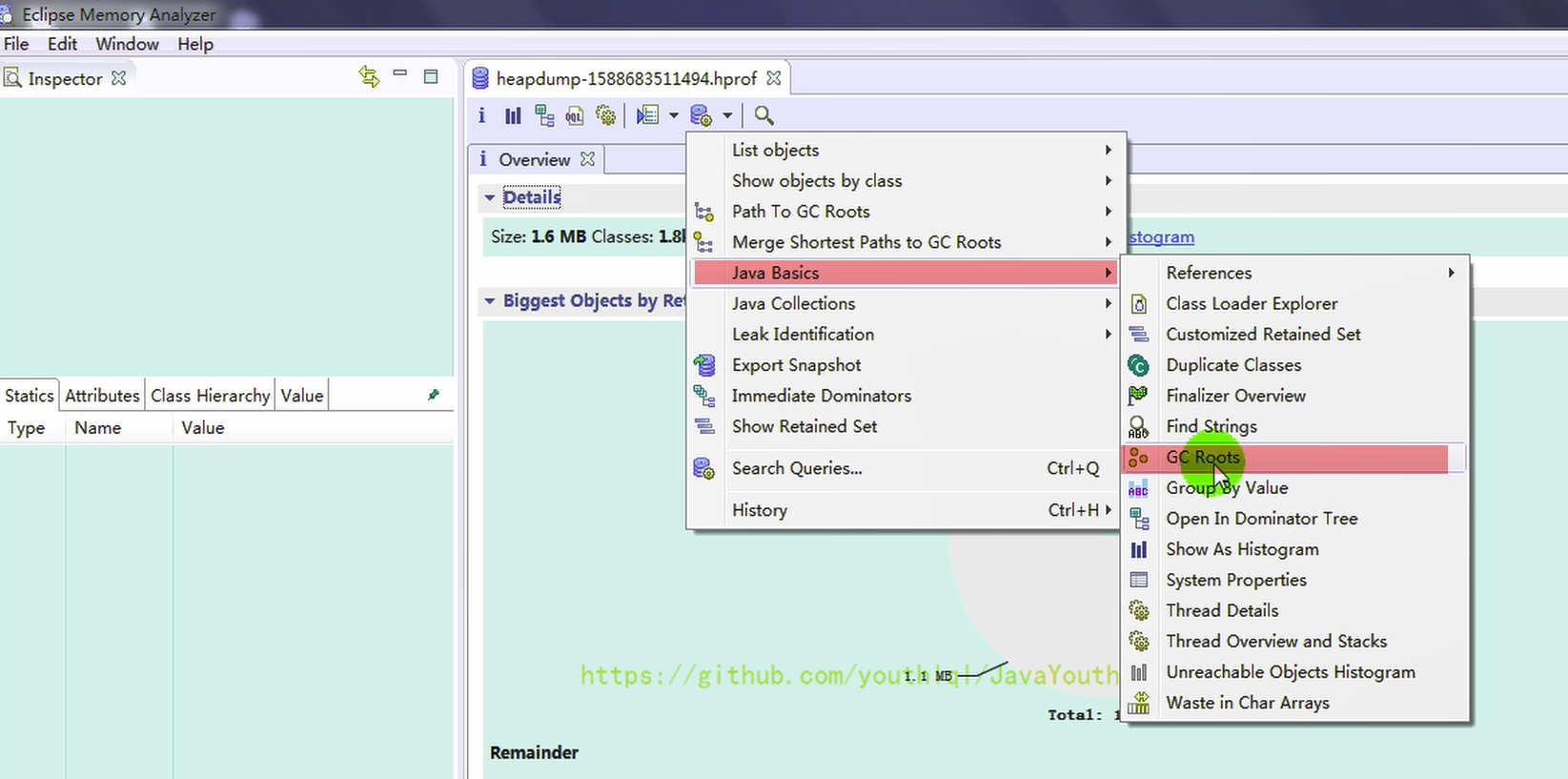
3、第一次捕捉堆內存快照時,GC Roots 中包含我們定義的兩個局部變量,類型分別為 ArrayList 和 Date,Total:21
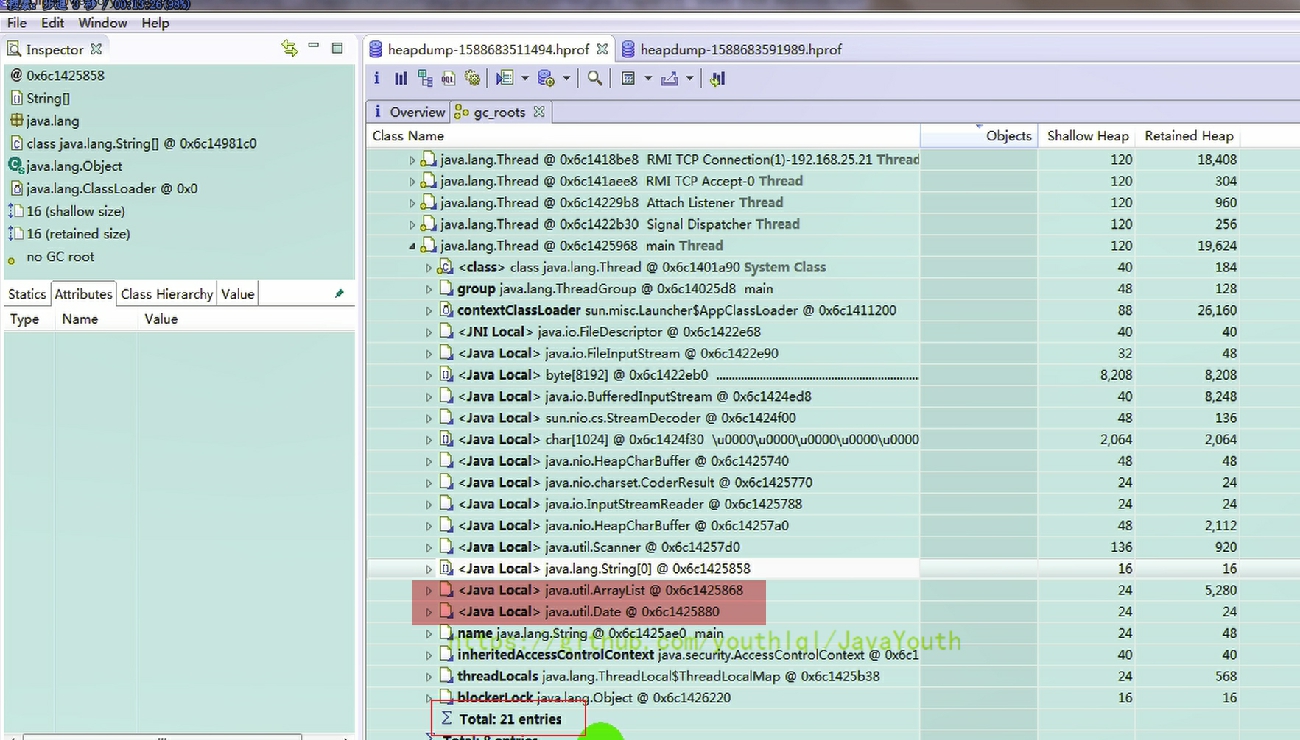
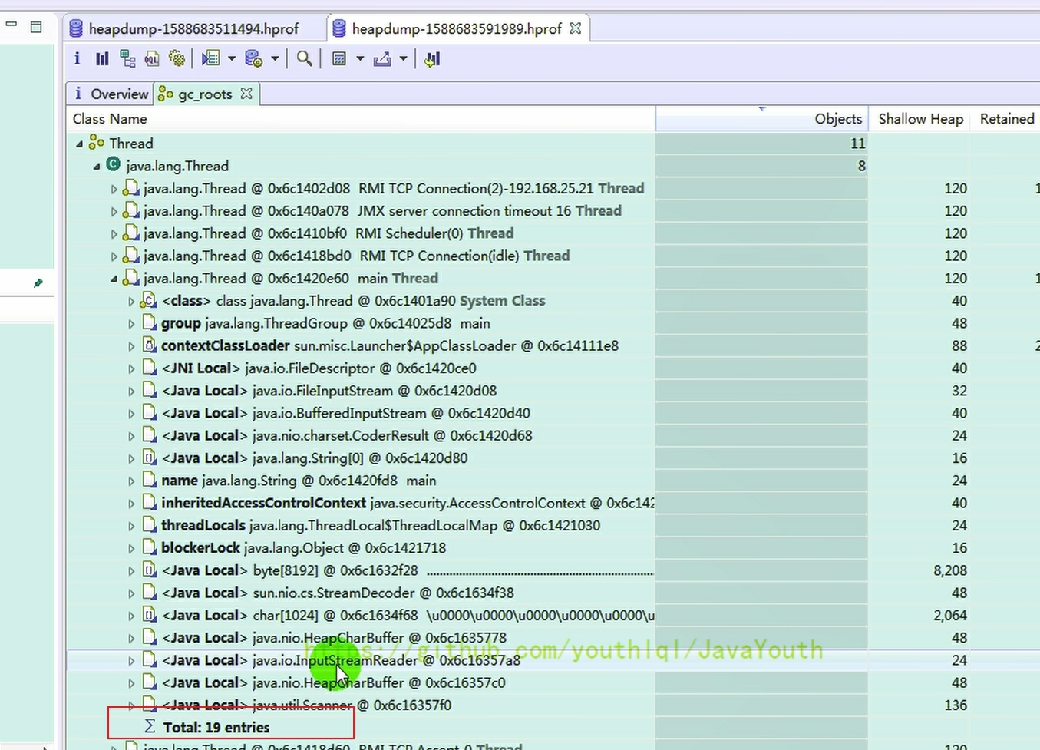
4、打開第二個dump文件,第二次捕獲內存快照時,由于兩個局部變量引用的對象被釋放,所以這兩個局部變量不再作為 GC Roots ,從 Total Entries = 19 也可以看出(少了兩個 GC Roots)
JProfiler GC Roots 溯源
1、在實際開發中,我們很少會查看所有的GC Roots。一般都是查看某一個或幾個對象的GC Root是哪個,這個過程叫GC Roots 溯源
2、下面我們使用使用 JProfiler 進行 GC Roots 溯源演示
依然用下面這個代碼
public class GCRootsTest {public static void main(String[] args) {List<Object> numList = new ArrayList<>();Date birth = new Date();for (int i = 0; i < 100; i++) {numList.add(String.valueOf(i));try {Thread.sleep(10);} catch (InterruptedException e) {e.printStackTrace();}}System.out.println("數據添加完畢,請操作:");new Scanner(System.in).next();numList = null;birth = null;System.out.println("numList、birth已置空,請操作:");new Scanner(System.in).next();System.out.println("結束");} }1、
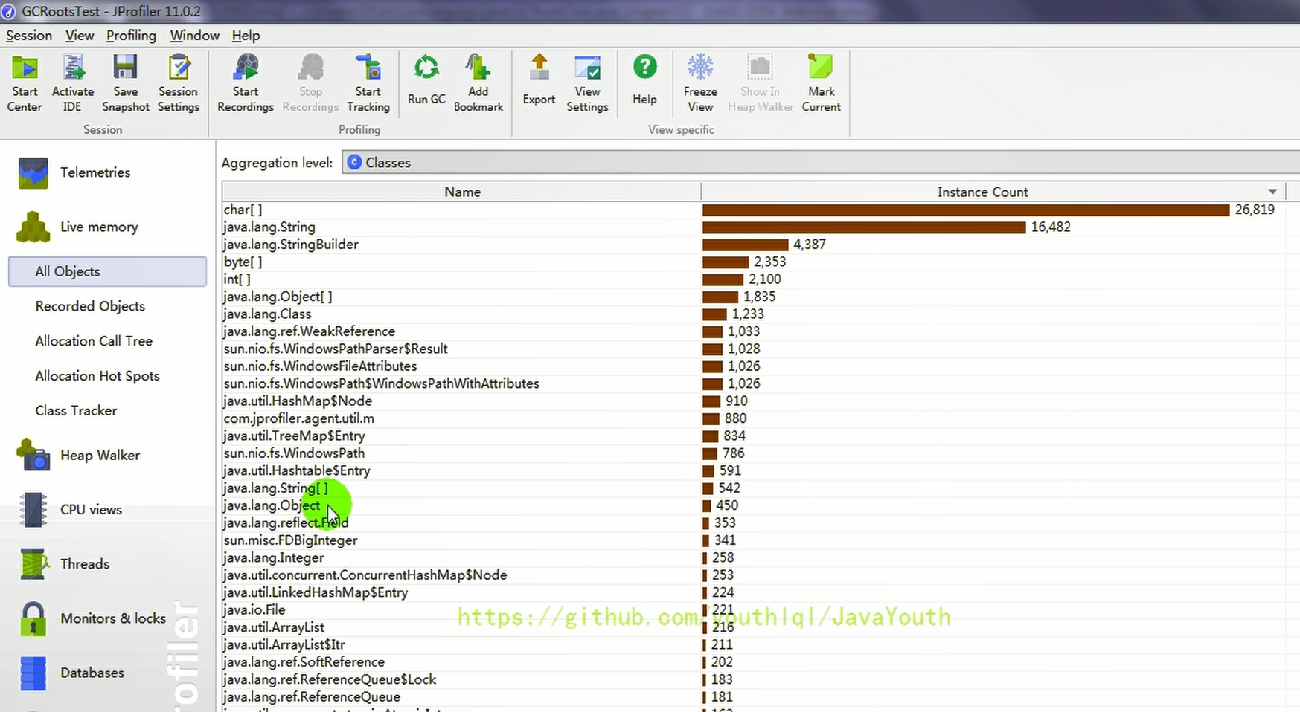
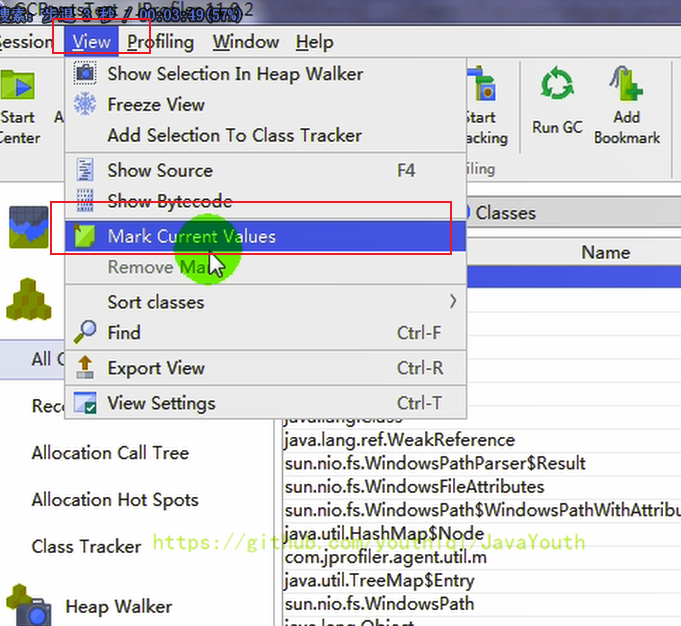
2、
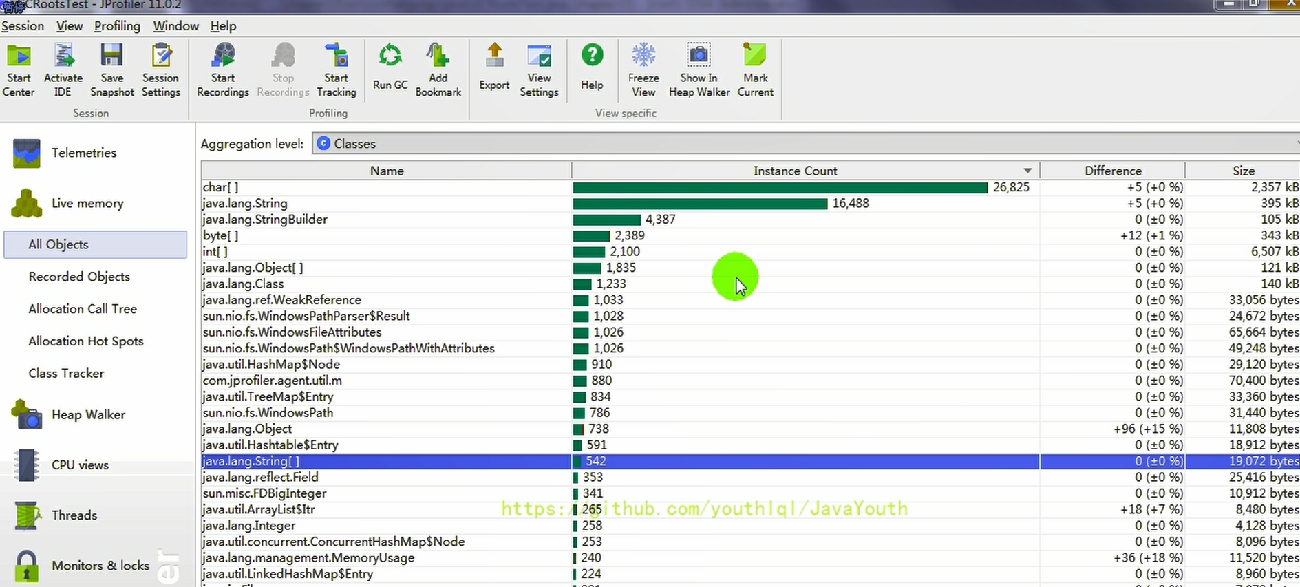
可以發現顏色變綠了,可以動態的看變化
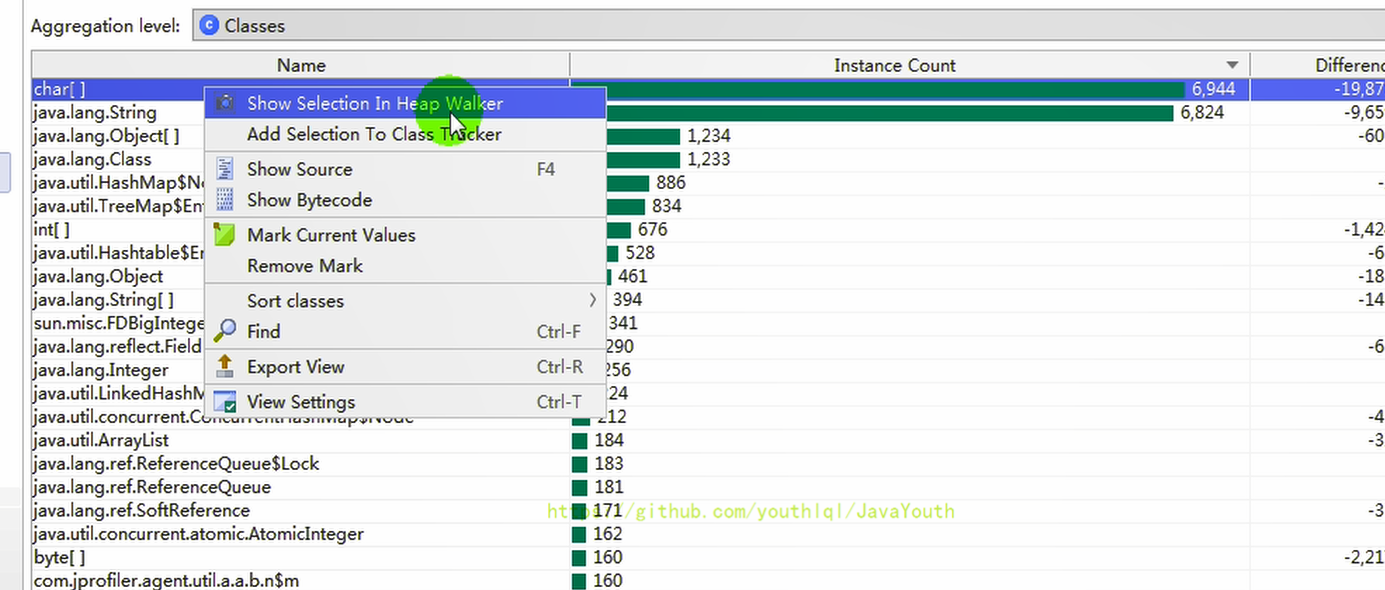
3、右擊對象,選擇 Show Selection In Heap Walker,單獨的查看某個對象
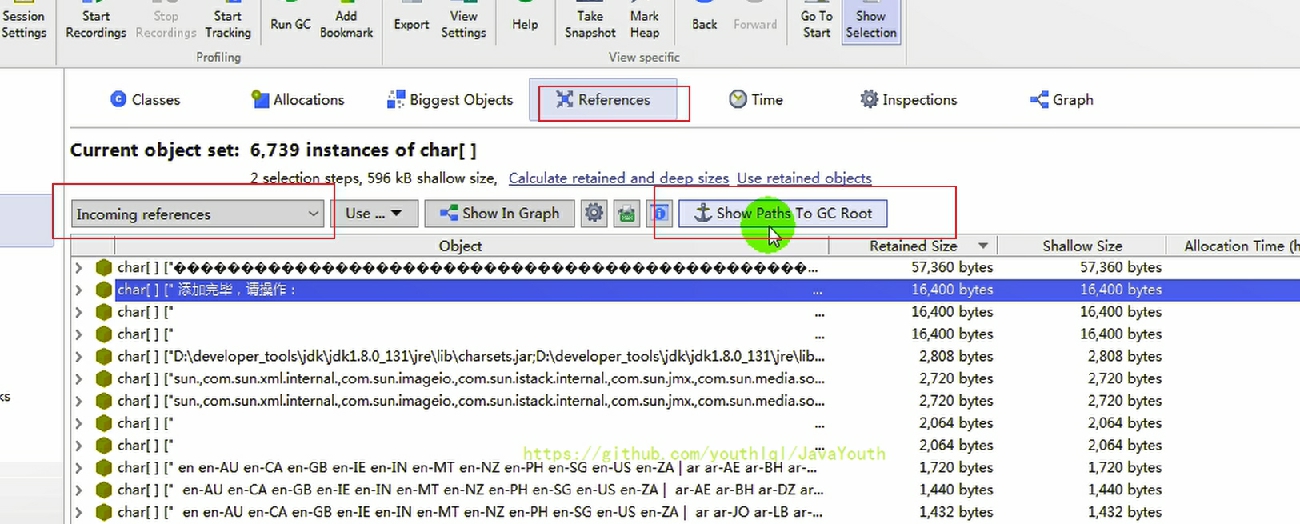
4、選擇Incoming References,表示追尋 GC Roots 的源頭
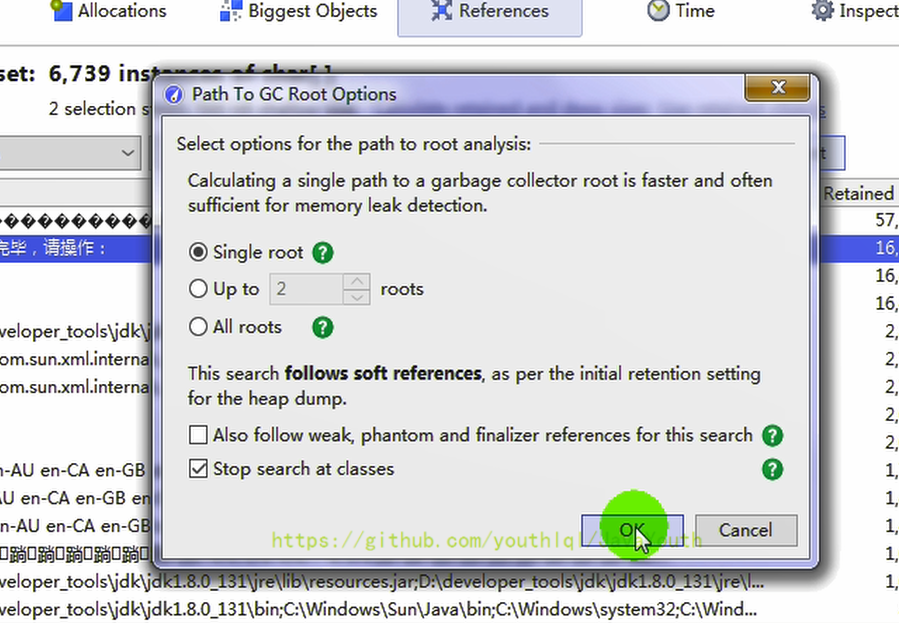
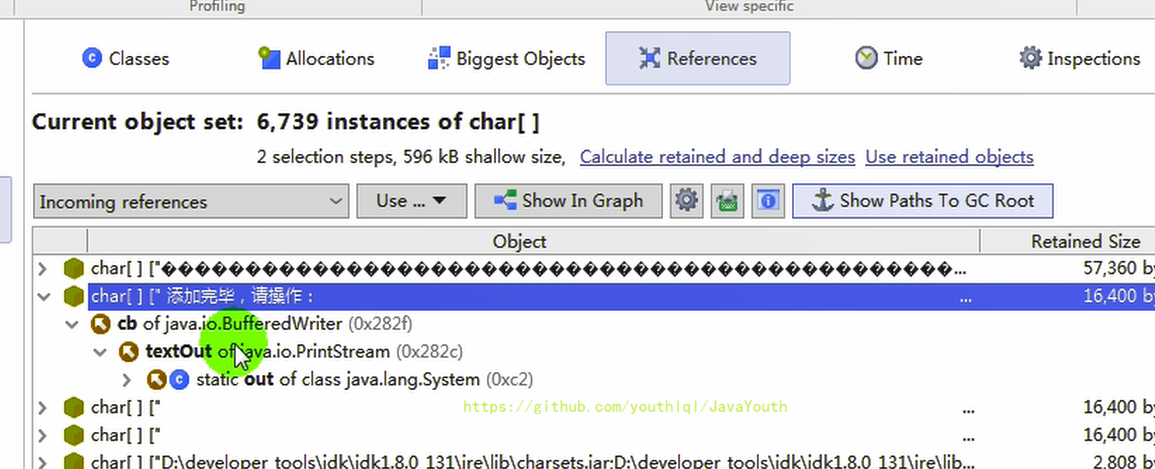
點擊Show Paths To GC Roots,在彈出界面中選擇默認設置即可
JProfiler 分析 OOM
這里是簡單的講一下,后面篇章會詳解
/*** -Xms8m -Xmx8m * -XX:+HeapDumpOnOutOfMemoryError 這個參數的意思是當程序出現OOM的時候就會在當前工程目錄生成一個dump文件*/ public class HeapOOM {byte[] buffer = new byte[1 * 1024 * 1024];//1MBpublic static void main(String[] args) {ArrayList<HeapOOM> list = new ArrayList<>();int count = 0;try{while(true){list.add(new HeapOOM());count++;}}catch (Throwable e){System.out.println("count = " + count);e.printStackTrace();}} }程序輸出日志
com.atguigu.java.HeapOOM java.lang.OutOfMemoryError: Java heap space Dumping heap to java_pid14608.hprof ... java.lang.OutOfMemoryError: Java heap spaceat com.atguigu.java.HeapOOM.<init>(HeapOOM.java:12)at com.atguigu.java.HeapOOM.main(HeapOOM.java:20) Heap dump file created [7797849 bytes in 0.010 secs] count = 6打開這個dump文件
1、看這個超大對象
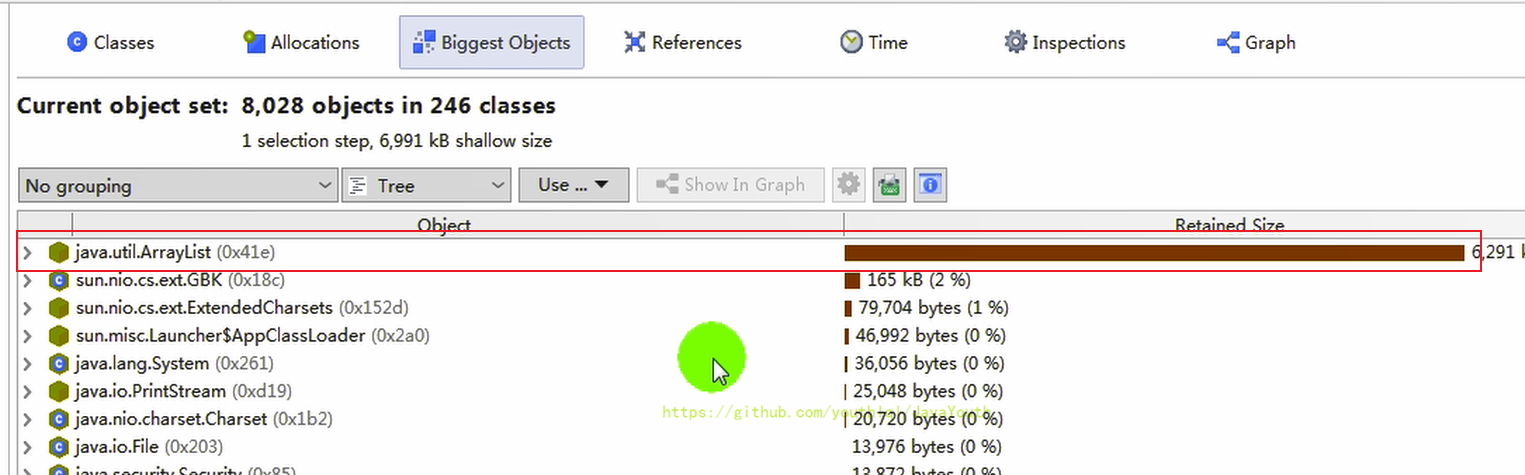
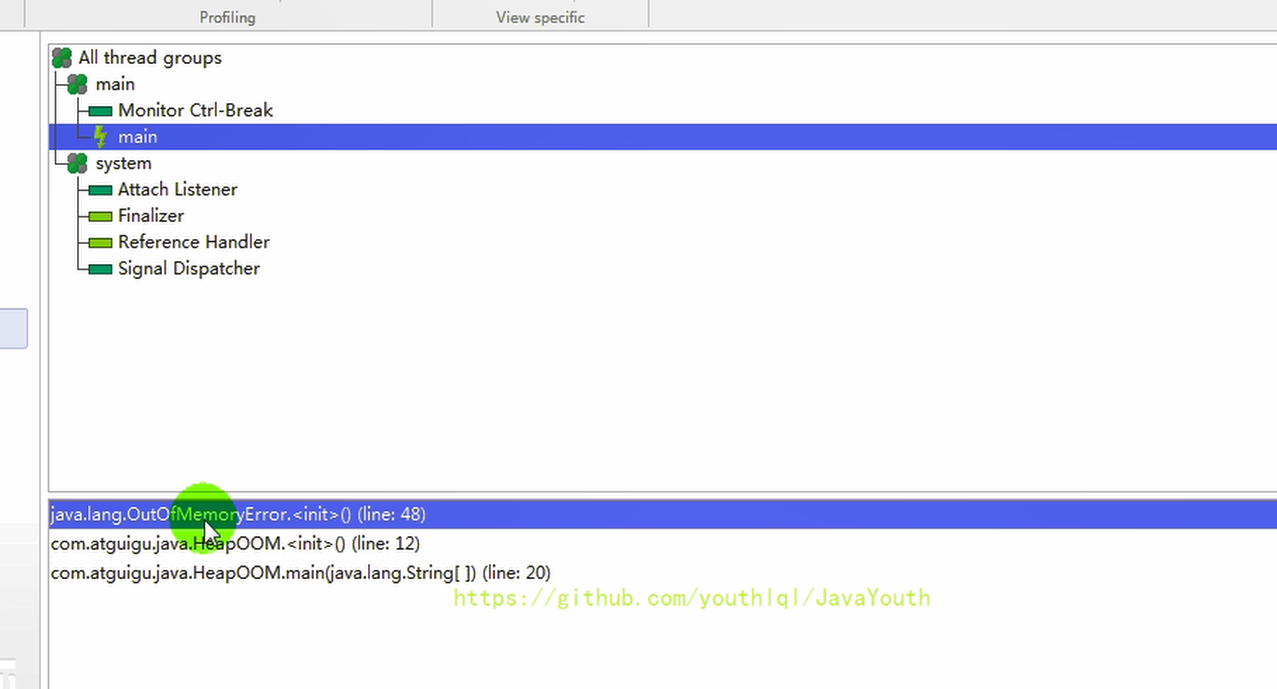
2、揪出 main() 線程中出問題的代碼
清除階段:標記-清除算法
垃圾清除階段
- 當成功區分出內存中存活對象和死亡對象后,GC接下來的任務就是執行垃圾回收,釋放掉無用對象所占用的內存空間,以便有足夠的可用內存空間為新對象分配內存。目前在JVM中比較常見的三種垃圾收集算法是
背景
標記-清除算法(Mark-Sweep)是一種非常基礎和常見的垃圾收集算法,該算法被J.McCarthy等人在1960年提出并并應用于Lisp語言。
執行過程
當堆中的有效內存空間(available memory)被耗盡的時候,就會停止整個程序(也被稱為stop the world),然后進行兩項工作,第一項則是標記,第二項則是清除
- 注意:標記的是被引用的對象,也就是可達對象,并非標記的是即將被清除的垃圾對象
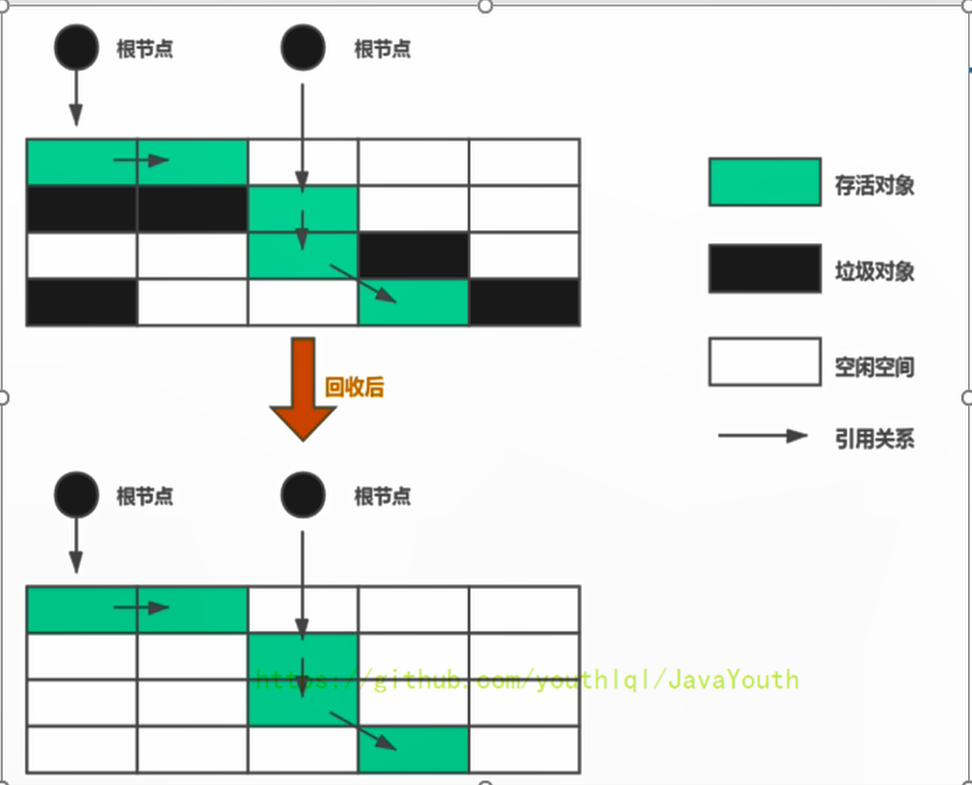
標記-清除算法的缺點
注意:何為清除?
這里所謂的清除并不是真的置空,而是把需要清除的對象地址保存在空閑的地址列表里。下次有新對象需要加載時,判斷垃圾的位置空間是否夠,如果夠,就存放(也就是覆蓋原有的地址)。
關于空閑列表是在為對象分配內存的時候提過:
- 采用指針碰撞的方式進行內存分配
- 虛擬機需要維護一個空閑列表
- 采用空閑列表分配內存
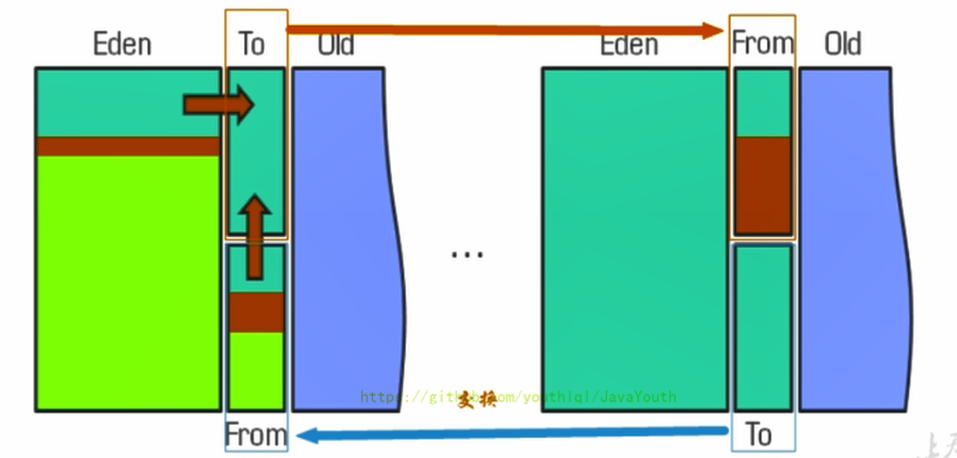
清除階段:復制算法
背景
核心思想
將活著的內存空間分為兩塊,每次只使用其中一塊,在垃圾回收時將正在使用的內存中的存活對象復制到未被使用的內存塊中,之后清除正在使用的內存塊中的所有對象,交換兩個內存的角色,最后完成垃圾回收
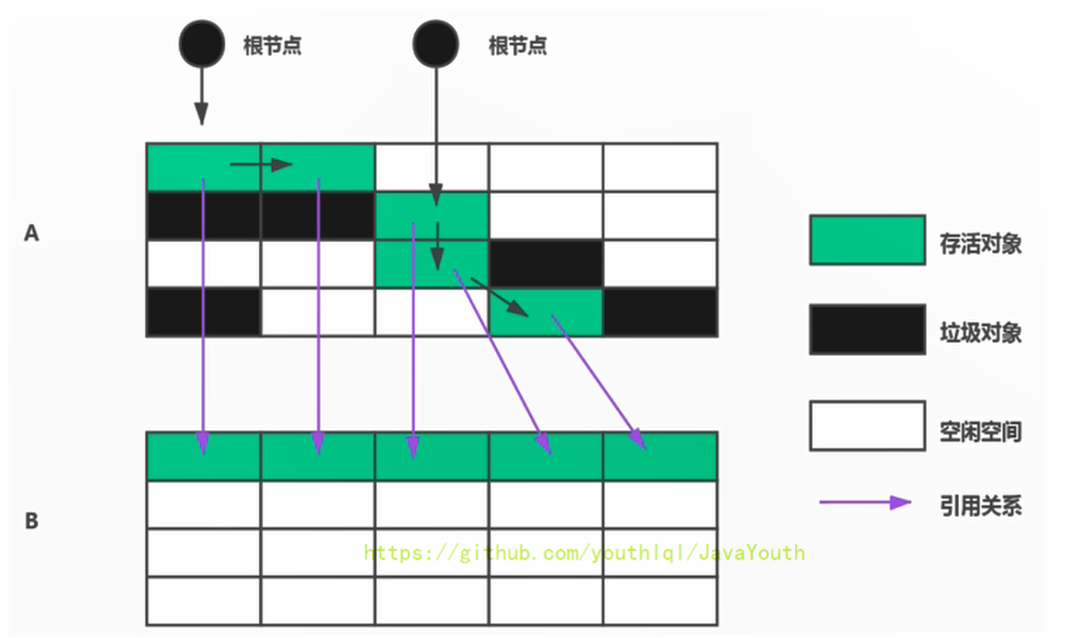
新生代里面就用到了復制算法,Eden區和S0區存活對象整體復制到S1區
復制算法的優缺點
優點
缺點
復制算法的應用場景
清除階段:標記-壓縮算法
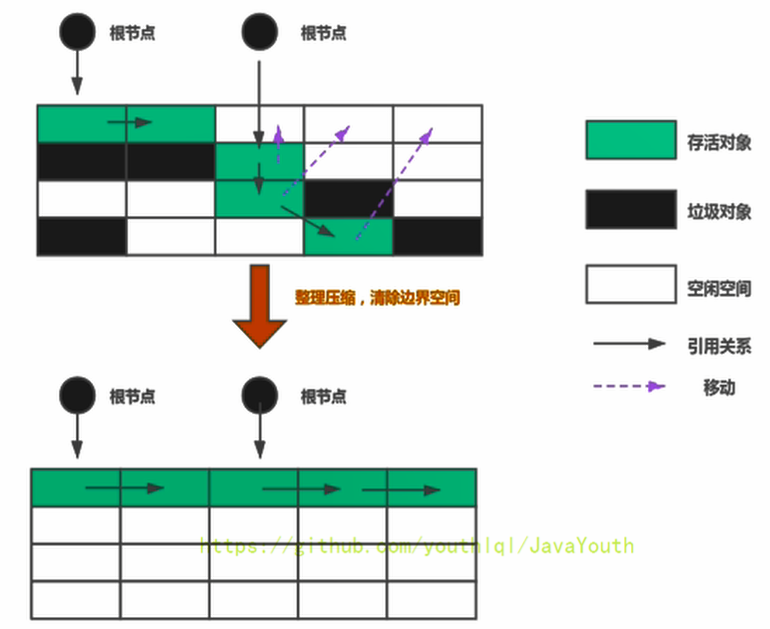
標記-壓縮(或標記-整理、Mark - Compact)算法
背景
執行過程
標記-壓縮算法與標記-清除算法的比較
標記-壓縮算法的優缺點
優點
缺點
垃圾回收算法小結
對比三種清除階段的算法
| | 標記清除 | 標記整理 | 復制 |
| — | — | — | — |
| 速率 | 中等 | 最慢 | 最快 |
| 空間開銷 | 少(但會堆積碎片) | 少(不堆積碎片) | 通常需要活對象的2倍空間(不堆積碎片) |
| 移動對象 | 否 | 是 | 是 |
分代收集算法
Q:難道就沒有一種最優的算法嗎?
A:無,沒有最好的算法,只有最合適的算法
為什么要使用分代收集算法
- 比如Http請求中的Session對象、線程、Socket連接,這類對象跟業務直接掛鉤,因此生命周期比較長。
- 但是還有一些對象,主要是程序運行過程中生成的臨時變量,這些對象生命周期會比較短,比如:String對象,由于其不變類的特性,系統會產生大量的這些對象,有些對象甚至只用一次即可回收。
目前幾乎所有的GC都采用分代手機算法執行垃圾回收的
在HotSpot中,基于分代的概念,GC所使用的內存回收算法必須結合年輕代和老年代各自的特點。
- 年輕代特點:區域相對老年代較小,對象生命周期短、存活率低,回收頻繁。
- 這種情況復制算法的回收整理,速度是最快的。復制算法的效率只和當前存活對象大小有關,因此很適用于年輕代的回收。而復制算法內存利用率不高的問題,通過hotspot中的兩個survivor的設計得到緩解。
- 老年代特點:區域較大,對象生命周期長、存活率高,回收不及年輕代頻繁。
- 這種情況存在大量存活率高的對象,復制算法明顯變得不合適。一般是由標記-清除或者是標記-清除與標記-整理的混合實現。
- Mark階段的開銷與存活對象的數量成正比。
- Sweep階段的開銷與所管理區域的大小成正相關。
- Compact階段的開銷與存活對象的數據成正比。
增量收集算法和分區算法
增量收集算法
上述現有的算法,在垃圾回收過程中,應用軟件將處于一種Stop the World的狀態。在Stop the World狀態下,應用程序所有的線程都會掛起,暫停一切正常的工作,等待垃圾回收的完成。如果垃圾回收時間過長,應用程序會被掛起很久,將嚴重影響用戶體驗或者系統的穩定性。為了解決這個問題,即對實時垃圾收集算法的研究直接導致了增量收集(Incremental Collecting)算法的誕生。
增量收集算法基本思想
增量收集算法的缺點
使用這種方式,由于在垃圾回收過程中,間斷性地還執行了應用程序代碼,所以能減少系統的停頓時間。但是,因為線程切換和上下文轉換的消耗,會使得垃圾回收的總體成本上升,造成系統吞吐量的下降。
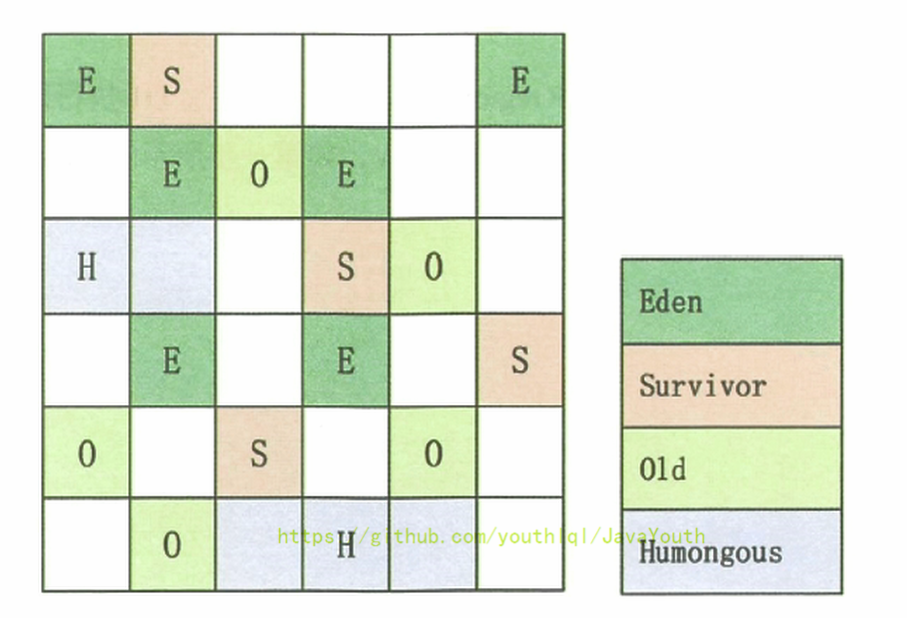
分區算法
主要針對G1收集器來說的
寫在最后
注意,這些只是基本的算法思路,實際GC實現過程要復雜的多,目前還在發展中的前沿GC都是復合算法,并且并行和并發兼備。
總結

- 上一篇: python重复输入上面指令_stdin
- 下一篇: expressjs路由和Nodejs服务