数据结构与算法(python版)
最近學習數據結構,對于從未接觸過數據結構的我來說,老師不僅講解理論,還有代碼的逐層分析,非常不錯,受益匪淺!!!(以下是學習記錄)
黑馬程序員孔德海老師教程
目錄
- 重點+基礎語法
- 時間復雜度(主要關注最壞時間復雜度)
- time.it,list,dic內置函數
- 數據結構
- 順序表
- 順序表的2個形式
- 順序表的結構與實現
- 順序表數據區擴充
- 順序表的操作
- python_list使用順序表數據結構
- 鏈表
- 單鏈表的實現
- 指定位置添加元素
- 查找節點是否存在
- 刪除節點
- 鏈表與順序表的對比
- 雙向鏈表
- 單向循環鏈表
- length(self)返回鏈表長度
- 頭部添加節點
- 棧
- 隊列
- 排序
- 冒泡排序O(n2)穩定
- 選擇排序O(n2)不穩定
- 插入排序O(n2)穩定
- 希爾排序
- 快速排序(不穩定)
- 歸并排序
- 排序算法效率比較
- 搜索
- 樹
- 樹的存儲
- 應用
- 二叉樹的節點表示以及樹的創建
- 二叉樹的遍歷
- 廣度優先遍歷(層次遍歷)
- 深度優先遍歷
- 根據數據畫樹圖
- 樹的補充
- 二叉排序樹(BST)
- 平衡二叉樹(AVL)
- 紅黑樹
- 多路查找樹
- B-樹(多路平衡查找樹)
- B+樹
重點+基礎語法
如a=5 a=“s” a=Person() a=f 方法
java基本數據類型中,變量a存放的是數值。引用數據類型(對象,數組,集合)的變量a存放的是地址。
#1 strat=time.time()時間復雜度(主要關注最壞時間復雜度)
不同方法間的復雜度
import time start= time.time() for i in range(0,1001):for j in range(0,1001):for k in range(0,1001):if i+j+k==1000 and i**2+j**2==k**2:print(i,j,k) end = time.time() print("總開銷:",end-start)#總開銷: 126.49699997901917start1= time.time() for i in range(0,1001):for j in range(0,1001):k=1000-i-jif i**2+j**2==k**2:print(i,j,k) end1= time.time() print("總開銷:",end1-start1)#總開銷: 1.0120000839233398大O表示法,只記錄最顯著特征O(n)=nxn
比如對一個list排序,無序的復雜度要高于有序
基本步驟:順序,條件(取T最大值),循環
li.append()不能看成一步,只有分析函數中的封裝才能看到append的時間復雜度
time.it,list,dic內置函數
from timeit import Timer def test3():l = [i for i in range(1000)] t3 = Timer("test3()", "from __main__ import test3")#1函數名,2import,因為這個Timer不一定在這里運行 print("comprehension ",t3.timeit(number=10000), "seconds")#test3()執行10000次后,10000次總的執行時間import time start=time.time()#從1970年到現在的計時秒數 end=time.time()-start#返回秒對于上例使用不同方法實現時
1. ('list(range(1000)) ', 0.014147043228149414, 'seconds') ('l = [i for i in range(1000)]', 0.05671119689941406, 'seconds') ('li.append ', 0.13796091079711914, 'seconds') ('concat加 ', 1.7890608310699463, 'seconds') 2.由于數據的存儲方式不同,導致插頭部和尾部 append()#2.159s insert(0,i)#30.00s pop(end)#0.00023,對尾部彈出 pop(0)#1.91數據結構
數據是一個抽象的概念,將其分類后得到程序語言的基本類型,如int,float,char。數據結構指對數據的一種封裝組成,如高級數據結構list,字典。數據結構就是一個類的概念,數據結構有順序表、鏈表、棧、隊列、樹。
算法復雜度只考慮的是運行的步驟,數據結構要與數據打交道。數據保存的方式不同決定了算法復雜度
程序 = 數據結構 + 算法
總結:算法是為了解決實際問題而設計的,數據結構是算法需要處理的問題載體
抽象數據類型(Abstract Data Type)
抽象數據類型(ADT)的含義是指一個數學模型以及定義在此數學模型上的一組操作。
== 代碼編寫注意==
2.對于鏈表要先接入新的node,再打斷原來的,要注意順序
下面講的各種表都是一種數據的封裝結構
順序表
順序表+鏈表=線性表:一根線串起來,兩種表都是用來存數據的
順序表的2個形式
計算機最小尋址單位是1字節,就是一個字節,才有一個地址,所有的地址都是統一大小0x27 4個字節
對于存放一個含有相同類型元素的list來講,用順序表封裝成一個數據結構。
元素內置順序表,是指存儲的數據類型都是一樣,這樣為每個元素開辟的空間都是一樣大的,在根據index找元素的時候
如list1=[1,2,3], 可以根據list的首地址0x12,很容易計算要查詢元素的物理地址=0x12+index x 4.
元素外置, 指存的數據類型不一樣,如list2=[1,3,“b”,4,“ccc”]
順序表的結構與實現
對于python來講已經做好封裝,不需要寫容量,元素個數
so常用的是分離式
順序表數據區擴充
如果數據要來回增,刪,導致空間不穩定,所以有了策略
順序表的操作
python_list使用順序表數據結構
1.表頭與數據分離式 2.因為一個list中有int,也有字符所以用的是元素外置 3.動態順序中的倍數擴充
鏈表
# cur做判斷,邏輯(不是指針)走到最后一個元素時,里面的方法體是執行的 # 用cur.next做判斷,while循環中是不執行的 # 如果發現少一次執行語句,可以手動打印,就不用完全在while循環中執行
java,c語言是需要中間變量temp,才能完成交換,只有python可以直接交換
單鏈表的實現
cur:指針地址
cur.elment:地址中的元素
cur=self._head先提出等式右邊地址,再給cur
多寫幾次單鏈表,有助理解,鏈表的運行過程
1. """單鏈表的結點,里面存放element區和next"""相當于元祖(element,next) class SingleNode(object):def __init__(self,item):# _item存放數據元素self.item = item# _next是下一個節點的標識self.next = None 2."""單鏈表數據結構類,具有以下功能"""相當于python中的list數據結構類,同時它也具有以下功能 class SingleLinkList(object):"""存放一個屬性P,好用來指向第一個節點"""def __init__(self,):self._head = None# _ 私有屬性,head=None說明P指向的單鏈表中沒有nodedef is_empty(self):"""判斷鏈表是否為空"""return self._head == Nonedef length(self):"""鏈表長度"""# current游標用來遍歷節點,初始時指向頭節點cur = self._head#直接指到第一個節點count = 0# 尾節點指向None,當未到達尾部時while cur != None:count += 1# 將cur后移一個節點cur = cur.next #相當于指向下一個節點return countdef travel(self):"""遍歷鏈表"""cur = self._head#直接指到第一個節點while cur != None:print cur.item,#打印第一個節點cur = cur.next#相當于指向下一個節點print ""def add(self, item):"""頭部添加元素"""# 先創建一個保存item值的節點node = SingleNode(item)# 將新節點的鏈接域next指向頭節點,即_head指向的位置,有先后,否則會丟失鏈node.next = self._head# 將鏈表的頭_head指向新節點self._head = nodedef append(self, item):"""尾部添加元素"""node = SingleNode(item)# 先判斷鏈表是否為空,若是空鏈表,則將_head指向新節點if self.is_empty():self._head = node#append時候,我只要保證把我的node地址給你就行,node.next不用管# 若不為空,則找到尾部,將尾節點的next指向新節點else:cur = self._headwhile cur.next != None:cur = cur.nextcur.next = node#直接將node送給cur.next,內部操作就是把node結點地址給他if __name__=="__main__":li=SingleLinkList()print(li.is_empty())print(li.length())node = SingleNode(3)li.append(11111)li.travel()3.使用node =Node(100)single_obj=SingleLinkList(node)#創建node,讓單鏈表指向它single_obj=SingleLinkList()#直接創建空鏈表指定位置添加元素
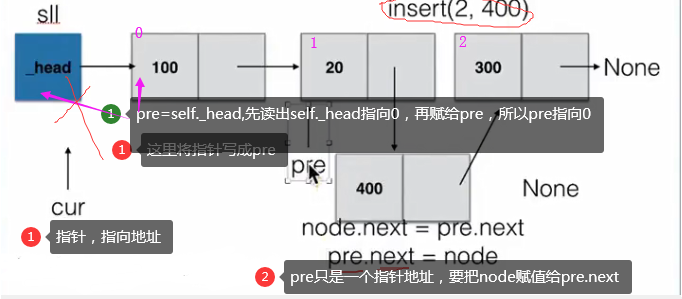
def insert(self, pos, item):"""指定位置添加元素"""# 若指定位置pos為第一個元素之前,則執行頭部插入if pos <= 0:self.add(item)# 若指定位置超過鏈表尾部,則執行尾部插入elif pos > (self.length()-1):self.append(item)# 找到指定位置else:node = SingleNode(item)count = 0# pre用來指向指定位置pos的前一個位置pos-1,初始從頭節點開始移動到指定位置pre = self._headwhile count < (pos-1):count += 1pre = pre.next# 先將新節點node的next指向插入位置的節點node.next = pre.next# 將插入位置的前一個節點的next指向新節點pre.next = node查找節點是否存在
def search(self,item):"""鏈表查找節點是否存在,并返回True或者False"""cur = self._headwhile cur != None:#一直往后走,起到遇到none停止if cur.item == item:return Truecur = cur.nextreturn False刪除節點
def remove(self,item):"""刪除節點"""cur = self._headpre = Nonewhile cur != None:# 找到了指定元素if cur.item == item:# 如果第一個就是刪除的節點if not pre:# 將頭指針指向頭節點的后一個節點self._head = cur.nextelse:# 將刪除位置前一個節點的next指向刪除位置的后一個節點pre.next = cur.nextbreakelse:# 繼續按鏈表后移節點pre = curcur = cur.next鏈表與順序表的對比
鏈表只能記錄頭節點地址,因此在訪問,尾部插,中間查時,都需要從頭節點,遍歷過去,所以復雜度O(n)
雙向鏈表
對于前面單向的,當前node不能查看其前面node的信息,所以引入雙向。添加,刪除node時,要保證每個node中的P,N都 給上值,如:中間插入
頭部插入元素
尾部插入元素
中間插入
單向循環鏈表
由于是循環列表,最后的尾結點不再是None結束,而是指向self._head
由于一開始將cur = self._head設成游標,所以判斷語句只能是cur.next
while cur.next != self._head
使用cur.next不能進到循環體,會導致少一次打印,可以手動打印
length(self)返回鏈表長度
def length(self):"""返回鏈表的長度"""# 如果鏈表為空,返回長度0if self.is_empty():return 0count = 1cur = self._head#指針啟動地址while cur.next != self._head:#因為循環鏈表最后一個node要帶有self._head,所以通過判斷是否有self._head來看是否一個循環結束count += 1cur = cur.nextreturn count頭部添加節點
def add(self, item):"""頭部添加節點"""node = Node(item)if self.is_empty():self._head = nodenode.next = self._headelse:#添加的節點指向_headnode.next = self._head# 移到鏈表尾部,將尾部節點的next指向nodecur = self._headwhile cur.next != self._head:cur = cur.nextcur.next = node#_head指向添加node的self._head = node棧
棧=杯
順序表,鏈表是用來存數據的
棧和隊列不考慮數據是如何存放的,棧stack,隊列是一種容器,執行什么樣的操作,抽象結構。
6*(2+3)
隊列
雙端隊列
兩個棧尾部放一起
是上面的擴展,含有的函數功能更多了
排序
排序算法的穩定性
冒泡排序O(n2)穩定
#可以將這個算法操作在順序表上(改變存儲位置),也可以操作在鏈表上(改變node節點) #不論list是什么要,O(n)=n^2 def bubble_sort(alist):for j in range(len(alist)-1,0,-1):#n-1,n-2,,,1# j表示每次遍歷需要比較的次數,是逐漸減小的for i in range(j):if alist[i] > alist[i+1]:alist[i], alist[i+1] = alist[i+1], alist[i]li = [54,26,93,17,77,31,44,55,20] bubble_sort(li) print(li)#加個檢測是否交換的優化的count,這樣復雜度為n #[1,2,3,4,5,9,8] def bubble_sort(alist):for j in range(len(alist)-1,0,-1):#n-1,n-2,,,1# j表示每次遍歷需要比較的次數,是逐漸減小的count=0for i in range(j):if alist[i] > alist[i+1]:alist[i], alist[i+1] = alist[i+1], alist[i]count+=1if 0 == count:contine li = [54,26,93,17,77,31,44,55,20] bubble_sort(li) print(li)冒泡是穩定的
選擇排序O(n2)不穩定
比如[5,5,2],就是不穩定的
選擇排序,插入排序,希爾排序是把序列分成兩部分,把其中的一部分元素往另外一部分做
插入排序O(n2)穩定
希爾排序
def shell_sort(list):n=len(list)gap=n//2 #gap=4while gap>=1:#gap一直變化到1for j in range(gap,n):#for控制的是gap=4時的4個子序列i=jwhile i >0:#跟之前插入排序一樣,對于一個序列的具體操作,與普通插入的區別就是gap步長if list[i]<list[i-gap]:list[i],list[i-gap]=list[i-gap],list[i]i-=gapelse:breakgap//=2#gap減半list = [54,26,93,17,77,31,44,55,20] shell_sort(list) print(list)快速排序(不穩定)
快速排序(英語:Quicksort),又稱劃分交換排序(partition-exchange sort),通過一趟排序將要排序的數據分割成獨立的兩部分,其中一部分的所有數據都比另外一部分的所有數據都要小,然后再按此方法對這兩部分數據分別進行快速排序,整個排序過程可以遞歸進行,以此達到整個數據變成有序序列。
注意
1.version2 中,兩個while有一個是等號,保證相同大小的元素放到mid的同一邊,這是快排設計的一個思想
用version2的思想寫代碼
歸并排序
def merge_sort(alist):if len(alist) <= 1:#遞歸的終止條件 return alist# 二分分解num = len(alist)/2left = merge_sort(alist[:num]) right = merge_sort(alist[num:])# 合并return merge(left,right)def merge(left, right):'''合并操作,將兩個有序數組left[]和right[]合并成一個大的有序數組'''#left與right的下標指針l, r = 0, 0result = []while l<len(left) and r<len(right):if left[l] < right[r]:result.append(left[l])l += 1else:result.append(right[r])r += 1result += left[l:]#當上面的while循環出來時,一個list的元素是取完的,保證將另外一個list余下的元素appendresult += right[r:]return result#是一個新list,不再使用之前list下標alist = [54,26,93,17,77,31,44,55,20] sorted_alist = mergeSort(alist) print(sorted_alist)遞歸時要注意縮進,這樣可以幫助理解
排序算法效率比較
搜索
二分法
前提,二分查找只能作用于有序列表
遞歸法:當list處理后得到的list,還想再進行同樣的操作,使用遞歸,但是不能無限遞歸下去,所以終止條件很重要,在這個例子中,要么alist[midpoint]=item,return True,要么 if len(alist) = 0: return False,用來退出遞歸
#遞歸法,每次生成一個新的list def binary_search(alist, item):if len(alist) == 0:return Falseelse:midpoint = len(alist)//2if alist[midpoint]==item:return Trueelse:if item<alist[midpoint]:return binary_search(alist[:midpoint],item)else:return binary_search(alist[midpoint+1:],item)testlist = [0, 1, 2, 8, 13, 17, 19, 32, 42,] print(binary_search(testlist, 3)) print(binary_search(testlist, 13))binary_search([0, 1, 2, 8, 13, 17, 19, 32, 42,],item=3)midpoint=43<13binary_search([0, 1, 2, 8],item=3)midpoint=23>2binary_search([8],item=3)midpoint=1//2=03<8binary_search([],item=3)#a=[1,2,3,4] print(a[5:])會返回空列表return False非遞歸
遞歸法,調用函數自身,每次生成一個新的list,然后在list上操作.非遞歸法使用的是同一個list,所以first,last下標很重要,在while循環中,不斷更新first,last值來實現對于list的取值控制
樹
和前面的二分查找是一樣的
樹的存儲
應用
二叉樹的節點表示以及樹的創建
self.root = root#保存一個根節點,可以有,也可以沒有,如果有的話說明self.root后面跟著一串數據,然后.append,在這個基礎上進行加.如果self.root=None,self.root = node,為樹創建第一個節點
A為第一層,2^ 0, 2^1, ,2^2
寫完代碼后,要分析下特殊情況是否可以跑通,若不能的話,再寫特殊語句對待
廣度優先的add實現的二茶樹->考察隊列,先入先出
二叉樹的遍歷
廣度優先遍歷(層次遍歷)
def breadth_travel(self):"""利用隊列實現樹的層次遍歷"""if self.root == None:returnqueue = []queue.append(root)while queue:#這個queue最后是要為空的(上面的那么add的queue,由于滿足條件就會return,所以不會空)node = queue.pop(0)print node.elem,if node.lchild != None:queue.append(node.lchild)if node.rchild != None:queue.append(node.rchild)深度優先遍歷
每次把框縮小一開始0為根節點,然后1為根節點,然后3為根節點,根節點一直變動
根據數據畫樹圖
一定要中序:用來分割數據
前、后序:用來找根
樹的補充
只列出大綱,后序學習
二叉排序樹(BST)
平衡二叉樹(AVL)
特點:1.是二叉排序樹 ⒉滿足每個結點的平衡因子絕對值<=1
紅黑樹
紅黑樹是一個“適度平衡”的二叉搜索樹,而非如AVL一般“嚴格”的平衡。(說它不嚴格是因為它不是嚴格控制左、右子樹高度或節點數之差小于等于1。)
面試常問:什么是紅黑樹?
1.每個節點只能是紅色或者黑色。
2.根節點必須是黑色。
3.紅色節點的子節點只能是黑色。
4.從任一節點到其每個葉子節點,的所有路徑上,包含黑色節點的數目相同。
多路查找樹
B-樹(多路平衡查找樹)
視頻增刪查
B樹又稱為多路平衡查找樹,是一種組織和維護外存文件系統非常有效的數據結構。比如數據庫的索引。
B+樹
b+樹和b樹的區別_B+樹和B/B樹的區別?Mysql為啥用B+樹來做索引?
b+樹適合范圍查找,比如找年齡在18-22歲的人的信息,先用隨機查找找到18,再用順序查到到22,速度極快,這也是為啥Mysql用B+樹來做索引。
主要區別:
1.所有關鍵字都會在在葉子節點出現
2.內部節點(非葉子節點)不存儲數據(b樹內部節點是存儲data的),數據只在葉子節點存儲(葉子節指其下沒有子樹了)
3.所有葉子結點構成了一個鏈指針,而且所有的葉子節點按照順序排列。
B+樹比B樹有什么優勢?
1.每一層更寬,更胖,存儲的數據更多。因為B+樹只存儲關鍵字,而不存儲多余data.所以B+樹的每一層相比B樹能存儲更多節點。
2.所有的節點都會在葉子節點上出現,查詢效率更穩定。因為B+樹節點上沒有數據,所以要查詢數據就必須到葉子節點上,所以查詢效率比B樹穩定。而在 B 樹中,非葉子節點也會存儲數據,這樣就會造成查詢效率不穩定的情況,有時候訪問到了非葉子節點就可以找到關鍵字,而有時需要訪問到葉子節點才能找到關鍵字。
3.查詢效率比B樹高。因為B+樹更矮,更胖,所以和磁盤交互的次數比B樹更少,而且B+樹通過底部的鏈表也可以完成遍歷,但是B樹需要找到每個節點才能遍歷,所以B+樹效率更高。
總結:
1.存的多 2.查詢穩定 3.查的快
總結
以上是生活随笔為你收集整理的数据结构与算法(python版)的全部內容,希望文章能夠幫你解決所遇到的問題。

- 上一篇: android 75 新闻列表页面
- 下一篇: latex 插入Python代码