HDFS NameNode内存详解
前言
《HDFS NameNode內(nèi)存全景》中,我們從NameNode內(nèi)部數(shù)據(jù)結(jié)構(gòu)的視角,對(duì)它的內(nèi)存全景及幾個(gè)關(guān)鍵數(shù)據(jù)結(jié)構(gòu)進(jìn)行了簡(jiǎn)單解讀,并結(jié)合實(shí)際場(chǎng)景介紹了NameNode可能遇到的問(wèn)題,還有業(yè)界進(jìn)行橫向擴(kuò)展方面的多種可借鑒解決方案。
事實(shí)上,對(duì)NameNode實(shí)施橫向擴(kuò)展前,會(huì)面臨常駐內(nèi)存隨數(shù)據(jù)規(guī)模持續(xù)增長(zhǎng)的情況,為此需要經(jīng)歷不斷調(diào)整NameNode內(nèi)存的堆空間大小的過(guò)程,期間會(huì)遇到幾個(gè)問(wèn)題:
- 當(dāng)前內(nèi)存空間預(yù)期能夠支撐多長(zhǎng)時(shí)間。
- 何時(shí)調(diào)整堆空間以應(yīng)對(duì)數(shù)據(jù)規(guī)模增長(zhǎng)。
- 增加多大堆空間。
另一方面NameNode堆空間又不能無(wú)止境增加,到達(dá)閾值后(與機(jī)型、JVM版本、GC策略等相關(guān))同樣會(huì)存在潛在問(wèn)題:
- 重啟時(shí)間變長(zhǎng)。
- 潛在的FGC風(fēng)險(xiǎn)。
由此可見(jiàn),對(duì)NameNode內(nèi)存使用情況的細(xì)粒度掌控,可以為優(yōu)化內(nèi)存使用或調(diào)整內(nèi)存大小提供更好的決策支持。
本文在前篇《HDFS NameNode內(nèi)存全景》文章的基礎(chǔ)上,針對(duì)前面的幾個(gè)問(wèn)題,進(jìn)一步對(duì)NameNode核心數(shù)據(jù)結(jié)構(gòu)的內(nèi)存使用情況進(jìn)行詳細(xì)定量分析,并給出可供參考的內(nèi)存預(yù)估模型。根據(jù)分析結(jié)果可有針對(duì)的優(yōu)化集群存儲(chǔ)資源使用模式,同時(shí)利用內(nèi)存預(yù)估模型,可以提前對(duì)內(nèi)存資源進(jìn)行合理規(guī)劃,為HDFS的發(fā)展提供數(shù)據(jù)參考依據(jù)。
內(nèi)存分析
NetworkTopology
NameNode通過(guò)NetworkTopology維護(hù)整個(gè)集群的樹(shù)狀拓?fù)浣Y(jié)構(gòu),當(dāng)集群?jiǎn)?dòng)過(guò)程中,通過(guò)機(jī)架感知(通常都是外部腳本計(jì)算)逐漸建立起整個(gè)集群的機(jī)架拓?fù)浣Y(jié)構(gòu),一般在NameNode的生命周期內(nèi)不會(huì)發(fā)生大變化。拓?fù)浣Y(jié)構(gòu)的葉子節(jié)點(diǎn)DatanodeDescriptor是標(biāo)識(shí)DataNode的關(guān)鍵結(jié)構(gòu),該類(lèi)繼承關(guān)系如圖1所示。
圖1 DatanodeDescriptor繼承關(guān)系
在64位JVM中,DatanodeDescriptor內(nèi)存使用情況如圖2所示(除特殊說(shuō)明外,后續(xù)對(duì)其它數(shù)據(jù)結(jié)構(gòu)的內(nèi)存使用情況分析均基于64位JVM)。
圖2 DatanodeDescriptor內(nèi)存使用詳解
由于DataNode節(jié)點(diǎn)一般會(huì)掛載多塊不同類(lèi)型存儲(chǔ)單元,如HDD、SSD等,圖2中storageMap描述的正是存儲(chǔ)介質(zhì)DatanodeStorageInfo集合,其詳細(xì)數(shù)據(jù)結(jié)構(gòu)如圖3所示。
圖3 DatanodeStorageInfo內(nèi)存使用詳解
除此之外,DatanodeDescriptor還包括一部分動(dòng)態(tài)內(nèi)存對(duì)象,如replicateBlocks、recoverBlocks和invalidateBlocks等與數(shù)據(jù)塊動(dòng)態(tài)調(diào)整相關(guān)的數(shù)據(jù)結(jié)構(gòu),pendingCached、cached和pendingUncached等與集中式緩存相關(guān)的數(shù)據(jù)結(jié)構(gòu)。由于這些數(shù)據(jù)均屬動(dòng)態(tài)的形式臨時(shí)存在,隨時(shí)會(huì)發(fā)生變化,所以這里沒(méi)有做進(jìn)一步詳細(xì)統(tǒng)計(jì)(結(jié)果存在少許誤差)。
根據(jù)前面的分析,假設(shè)集群中包括2000個(gè)DataNode節(jié)點(diǎn),NameNode維護(hù)這部分信息需要占用的內(nèi)存總量:
(64 + 114 + 56 + 109 ? 16)? 2000 = ~4MB
在樹(shù)狀機(jī)架拓?fù)浣Y(jié)構(gòu)中,除了葉子節(jié)點(diǎn)DatanodeDescriptor外,還包括內(nèi)部節(jié)點(diǎn)InnerNode描述集群拓?fù)浣Y(jié)構(gòu)中機(jī)架信息。
圖4 NetworkTopology拓?fù)浣Y(jié)構(gòu)內(nèi)部節(jié)點(diǎn)內(nèi)存使用詳解
對(duì)于這部分描述機(jī)架信息等節(jié)點(diǎn)信息,假設(shè)集群包括80個(gè)機(jī)架和2000個(gè)DataNode節(jié)點(diǎn),NameNode維護(hù)拓?fù)浣Y(jié)構(gòu)中內(nèi)部節(jié)點(diǎn)信息需要占用的內(nèi)存總量:
(44 + 48) ? 80 + 8 ? 2000 = ~25KB
從上面的分析可以看到,為維護(hù)集群的拓?fù)浣Y(jié)構(gòu)NetworkTopology,當(dāng)集群規(guī)模為2000時(shí),需要的內(nèi)存空間不超過(guò)5MB,按照接近線性增長(zhǎng)趨勢(shì),即使集群規(guī)模接近10000,這部分內(nèi)存空間~25MB,相比整個(gè)NameNode JVM的內(nèi)存開(kāi)銷(xiāo)微乎其微。
NameSpace
與傳統(tǒng)單機(jī)文件系統(tǒng)相似,HDFS對(duì)文件系統(tǒng)的目錄結(jié)構(gòu)也是按照樹(shù)狀結(jié)構(gòu)維護(hù),NameSpace保存的正是整個(gè)目錄樹(shù)及目錄樹(shù)上每個(gè)目錄/文件節(jié)點(diǎn)的屬性,包括:名稱(chēng)(name),編號(hào)(id),所屬用戶(hù)(user),所屬組(group),權(quán)限(permission),修改時(shí)間(mtime),訪問(wèn)時(shí)間(atime),子目錄/文件(children)等信息。
下圖5為Namespace中INode的類(lèi)圖結(jié)構(gòu),從類(lèi)圖可以看出,文件INodeFile和目錄INodeDirectory的繼承關(guān)系。其中目錄在內(nèi)存中由INodeDirectory對(duì)象來(lái)表示,并用List children成員列表來(lái)描述該目錄下的子目錄或文件;文件在內(nèi)存中則由INodeFile來(lái)表示,并用BlockInfo[] blocks數(shù)組表示該文件由哪些Blocks組成。其它屬性由繼承關(guān)系的各個(gè)相應(yīng)子類(lèi)成員變量標(biāo)識(shí)。
圖5 文件和目錄繼承關(guān)系
目錄和文件結(jié)構(gòu)在繼承關(guān)系中各屬性的內(nèi)存占用情況如圖6所示。
圖6 目錄和文件內(nèi)存使用詳解
除圖中提到的屬性信息外,一些附加如ACL等非通用屬性,沒(méi)有在統(tǒng)計(jì)范圍內(nèi)。在默認(rèn)場(chǎng)景下,INodeFile和INodeDirectory.withQuotaFeature是相對(duì)通用和廣泛使用到的兩個(gè)結(jié)構(gòu)。
根據(jù)前面的分析,假設(shè)HDFS目錄和文件數(shù)分別為1億,Block總量在1億情況下,整個(gè)Namespace在JVM中內(nèi)存使用情況:
Total(Directory) = (24 + 96 + 44 + 48) ? 100M + 8 ? num(total children) Total(Files) = (24 + 96 + 48) ? 100M + 8 ? num(total blocks) Total = (24 + 96 + 44 + 48) ? 100M + 8 ? num(total children) + (24 + 96 + 48) ? 100M + 8 ? num(total blocks) = ~38GB
關(guān)于預(yù)估方法的幾點(diǎn)說(shuō)明: 1. 對(duì)目錄樹(shù)結(jié)構(gòu)中所有的Directory均按照默認(rèn)INodeDirectory.withQuotaFeature結(jié)構(gòu)進(jìn)行估算,如果集群開(kāi)啟ACL/Snapshotd等特性,需增加這部分內(nèi)存開(kāi)銷(xiāo)。 2. 對(duì)目錄樹(shù)結(jié)構(gòu)中所有的File按照INodeFile進(jìn)行估算。 3. 從整個(gè)目錄樹(shù)的父子關(guān)系上看,num(total children)就是目錄節(jié)點(diǎn)數(shù)和文件節(jié)點(diǎn)數(shù)之和。 4. 部分?jǐn)?shù)據(jù)結(jié)構(gòu)中包括了字符串,按照均值長(zhǎng)度為8進(jìn)行預(yù)估,實(shí)際情況可能會(huì)稍大。
Namespace在JVM堆內(nèi)存空間中常駐,在NameNode的整個(gè)生命周期一直在內(nèi)存存在,同時(shí)為保證數(shù)據(jù)的可靠性,NameNode會(huì)定期對(duì)其進(jìn)行Checkpoint,將Namespace物化到外部存儲(chǔ)設(shè)備。隨著數(shù)據(jù)規(guī)模的增加,文件數(shù)/目錄樹(shù)也會(huì)隨之增加,整個(gè)Namespace所占用的JVM內(nèi)存空間也會(huì)基本保持線性同步增加。
BlocksMap
HDFS將文件按照一定的大小切成多個(gè)Block,為了保證數(shù)據(jù)可靠性,每個(gè)Block對(duì)應(yīng)多個(gè)副本,存儲(chǔ)在不同DataNode上。NameNode除需要維護(hù)Block本身的信息外,還需要維護(hù)從Block到DataNode列表的對(duì)應(yīng)關(guān)系,用于描述每一個(gè)Block副本實(shí)際存儲(chǔ)的物理位置,BlockManager中BlocksMap結(jié)構(gòu)即用于Block到DataNode列表的映射關(guān)系。BlocksMap內(nèi)部數(shù)據(jù)結(jié)構(gòu)如圖7所示。
圖7 BlockInfo繼承關(guān)系
BlocksMap經(jīng)過(guò)多次優(yōu)化形成當(dāng)前結(jié)構(gòu),最初版本直接使用HashMap解決從Block到BlockInfo的映射。由于在內(nèi)存使用、碰撞沖突解決和性能等方面存在問(wèn)題,之后使用重新實(shí)現(xiàn)的LightWeightGSet代替HashMap,該數(shù)據(jù)結(jié)構(gòu)本質(zhì)上也是利用鏈表解決碰撞沖突的HashTable,但是在易用性、內(nèi)存占用和性能等方面表現(xiàn)更好。關(guān)于引入LightWeightGSet細(xì)節(jié)可參考HDFS-1114。
與HashMap相比,為了盡可能避免碰撞沖突,BlocksMap在初始化時(shí)直接分配整個(gè)JVM堆空間的2%作為L(zhǎng)ightWeightGSet的索引空間,當(dāng)然2%不是絕對(duì)值,如果2%內(nèi)存空間可承載的索引項(xiàng)超出了Integer.MAX_VALUE/8(注:Object.hashCode()結(jié)果是int,對(duì)于64位JVM的對(duì)象引用占用8Bytes)會(huì)將其自動(dòng)調(diào)整到閾值上限。限定JVM堆空間的2%基本上來(lái)自經(jīng)驗(yàn)值,假定對(duì)于64位JVM環(huán)境,如果提供64GB內(nèi)存大小,索引項(xiàng)可超過(guò)1億,如果Hash函數(shù)適當(dāng),基本可以避免碰撞沖突。
BlocksMap的核心功能是通過(guò)BlockID快速定位到具體的BlockInfo,關(guān)于BlockInfo詳細(xì)的數(shù)據(jù)結(jié)構(gòu)如圖8所示。BlockInfo繼承自Block,除了Block對(duì)象中BlockID,numbytes和timestamp信息外,最重要的是該Block物理存儲(chǔ)所在的對(duì)應(yīng)DataNode列表信息triplets。
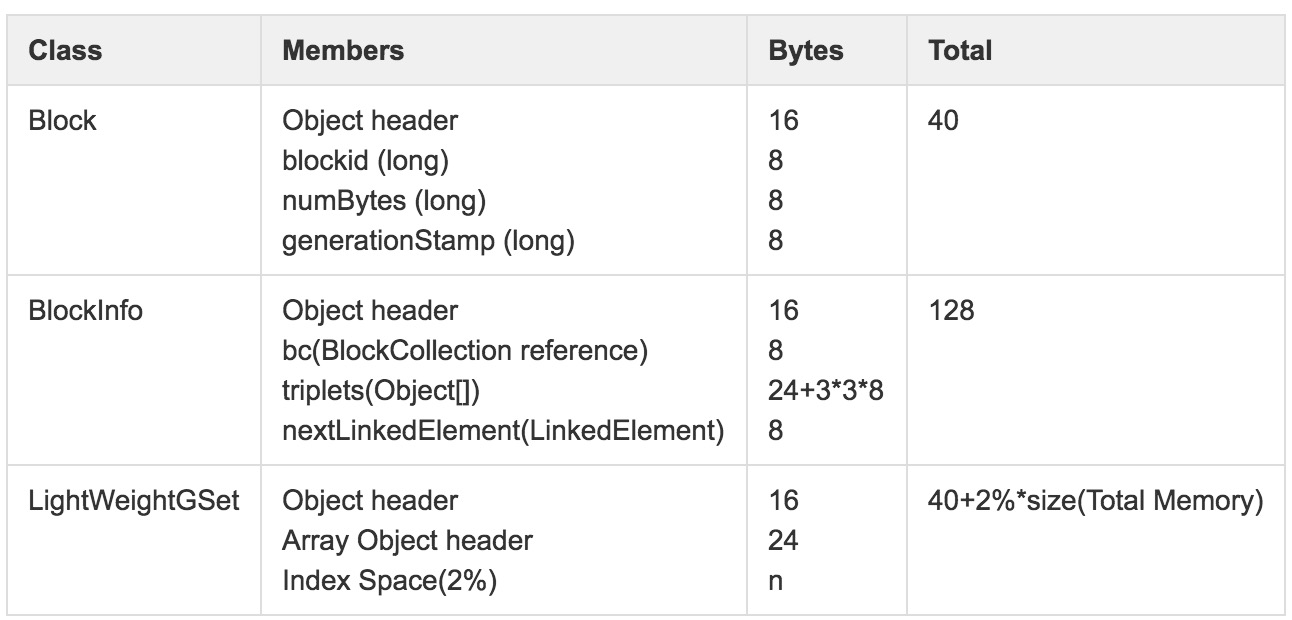圖8 BlocksMap內(nèi)存使用詳解
其中LightWeightGSet對(duì)應(yīng)的內(nèi)存空間全局唯一。盡管經(jīng)過(guò)LightWeightGSet優(yōu)化內(nèi)存占用,但是BlocksMap仍然占用了大量JVM內(nèi)存空間,假設(shè)集群中共1億Block,NameNode可用內(nèi)存空間固定大小128GB,則BlocksMap占用內(nèi)存情況:
16 + 24 + 2% ? 128GB +( 40 + 128 )? 100M = ~20GB
BlocksMap數(shù)據(jù)在NameNode整個(gè)生命周期內(nèi)常駐內(nèi)存,隨著數(shù)據(jù)規(guī)模的增加,對(duì)應(yīng)Block數(shù)會(huì)隨之增多,BlocksMap所占用的JVM堆內(nèi)存空間也會(huì)基本保持線性同步增加。
小結(jié)
NameNode內(nèi)存數(shù)據(jù)結(jié)構(gòu)非常豐富,除了前面詳細(xì)分析的核心數(shù)據(jù)結(jié)構(gòu)外,其實(shí)還包括如LeaseManager/SnapShotManager/CacheManager等管理的數(shù)據(jù),由于內(nèi)存使用非常有限,或特性未穩(wěn)定沒(méi)有開(kāi)啟,或沒(méi)有通用性,這里都不再展開(kāi)。
根據(jù)前述對(duì)NameNode內(nèi)存的預(yù)估,對(duì)比Hadoop集群歷史實(shí)際數(shù)據(jù):文件目錄總量~140M,數(shù)據(jù)塊總量~160M,NameNode JVM配置72GB,預(yù)估內(nèi)存使用情況:
Namespace:(24 + 96 + 44 + 48) ? 70M + 8 ? 140M + (24 + 96 + 48) ? 70M + 8 ? 160M = ~27GB BlocksMap:16 + 24 + 2% ? 72GB +( 40 + 128 )? 160M = ~26GB
說(shuō)明:這里按照目錄文件數(shù)占比1:1進(jìn)行了簡(jiǎn)化,基本與實(shí)際情況吻合,且簡(jiǎn)化對(duì)內(nèi)存預(yù)估結(jié)果影響非常小。
二者組合結(jié)果~53GB,結(jié)果與監(jiān)控?cái)?shù)據(jù)顯示常駐內(nèi)存~52GB基本相同,符合實(shí)際情況。
從前面討論可以看出,整個(gè)NameNode堆內(nèi)存中,占空間最大的兩個(gè)結(jié)構(gòu)為Namespace和BlocksMap,當(dāng)數(shù)據(jù)規(guī)模增加后,巨大的內(nèi)存占用勢(shì)必會(huì)給JVM內(nèi)存管理帶來(lái)挑戰(zhàn),甚至可能制約NameNode服務(wù)能力邊界。
針對(duì)Namespace和BlocksMap的空間占用規(guī)模,有兩個(gè)優(yōu)化方向:
- 合并小文件。使用Hive做數(shù)據(jù)生產(chǎn)時(shí),為避免嚴(yán)重的數(shù)據(jù)傾斜、人為調(diào)小分區(qū)粒度等一些特殊原因,可能會(huì)在HDFS上寫(xiě)入大量小文件,會(huì)給NameNode帶來(lái)潛在的影響。及時(shí)合并小文件,保持穩(wěn)定的目錄文件增長(zhǎng)趨勢(shì),可有效避免NameNode內(nèi)存抖動(dòng)。
- 適當(dāng)調(diào)整BlockSize。如前述,更少的Block數(shù)也可降低內(nèi)存使用,不過(guò)BlockSize調(diào)整會(huì)間接影響到計(jì)算任務(wù),需要進(jìn)行適當(dāng)?shù)臋?quán)衡。
對(duì)比其他Java服務(wù),NameNode場(chǎng)景相對(duì)特殊,需要對(duì)JVM部分默認(rèn)參數(shù)進(jìn)行適當(dāng)調(diào)整。比如Young/Old空間比例,為避免CMS GC降級(jí)到FGC影響服務(wù)可用性,適當(dāng)調(diào)整觸發(fā)CMS GC開(kāi)始的閾值等等。關(guān)于JVM相關(guān)參數(shù)調(diào)整策略的細(xì)節(jié)建議參考官方使用文檔。
這里,筆者根據(jù)實(shí)踐提供幾點(diǎn)NameNode內(nèi)存相關(guān)的經(jīng)驗(yàn)供參考:
- 根據(jù)元數(shù)據(jù)增長(zhǎng)趨勢(shì),參考本文前述的內(nèi)存空間占用預(yù)估方法,能夠大體得到NameNode常駐內(nèi)存大小,一般按照常駐內(nèi)存占內(nèi)存總量~60%調(diào)整JVM內(nèi)存大小可基本滿(mǎn)足需求。
- 為避免GC出現(xiàn)降級(jí)的問(wèn)題,可將CMSInitiatingOccupancyFraction調(diào)整到~70。
- NameNode重啟過(guò)程中,尤其是DataNode進(jìn)行BlockReport過(guò)程中,會(huì)創(chuàng)建大量臨時(shí)對(duì)象,為避免其晉升到Old區(qū)導(dǎo)致頻繁GC甚至誘發(fā)FGC,可適當(dāng)調(diào)大Young區(qū)(-XX:NewRatio)到10~15。
據(jù)了解,針對(duì)NameNode的使用場(chǎng)景,使用CMS內(nèi)存回收策略,將HotSpot JVM內(nèi)存空間調(diào)整到180GB,可提供穩(wěn)定服務(wù)。繼續(xù)上調(diào)有可能對(duì)JVM內(nèi)存管理能力帶來(lái)挑戰(zhàn),尤其是內(nèi)存回收方面,一旦發(fā)生FGC對(duì)應(yīng)用是致命的。這里提到180GB大小并不是絕對(duì)值,能否在此基礎(chǔ)上繼續(xù)調(diào)大且能夠穩(wěn)定服務(wù)不在本文的討論范圍。結(jié)合前述的預(yù)估方法,當(dāng)可用JVM內(nèi)存達(dá)180GB時(shí),可管理元數(shù)據(jù)總量達(dá)~700M,基本能夠滿(mǎn)足中小規(guī)模以下集群需求。
總結(jié)
本文在《HDFS NameNode內(nèi)存全景》基礎(chǔ)上,對(duì)NameNode內(nèi)存使用占比較高的幾個(gè)核心數(shù)據(jù)結(jié)構(gòu)進(jìn)行了詳細(xì)的介紹。在此基礎(chǔ)上,提供了可供參考的NameNode內(nèi)存數(shù)據(jù)空間占用預(yù)估模型:
Total = 198 ? num(Directory + Files) + 176 ? num(blocks) + 2% ? size(JVM Memory Size)
通過(guò)對(duì)NameNode內(nèi)存使用情況的定量分析,可為HDFS優(yōu)化和發(fā)展規(guī)劃提供可借鑒的數(shù)據(jù)參考依據(jù)。
參考文獻(xiàn)
[1] Apache Hadoop. https://hadoop.apache.org/. 2016. [2] Apache Issues. https://issues.apache.org/. 2016. [3] Apache Hadoop Source Code. https://github.com/apache/hadoop/tree/branch-2.4.1/. 2014. [4] HDFS NameNode內(nèi)存全景. http://tech.meituan.com/namenode.html. 2016. [5] Java HotSpot VM Options. http://www.oracle.com/technetwork/java/javase/tech/vmoptions-jsp-140102.html.
總結(jié)
以上是生活随笔為你收集整理的HDFS NameNode内存详解的全部?jī)?nèi)容,希望文章能夠幫你解決所遇到的問(wèn)題。

- 上一篇: 微服务系列:服务注册与发现的实现原理、及
- 下一篇: OpenTSDB 造成 Hbase 整点