车联网上云最佳实践(二)
云上對標架構及技術詳解
我們對傳統IDC應用架構進行分析之后,我們發現之前的系統架構存在一些不合理的地方導致了很多的痛點,為了解決這些痛點我們最終考慮上云。開始思考怎樣利用云上產品來解決目前遇到的痛點。例如
為了解決我們自建IDC底層基礎設施可靠性差的問題,我們改用云計算服務,基礎設施可靠性,異地容災,數據備份,數據安全等問題再也不用擔心;
- 為了解決存儲性能瓶頸以及用戶訪問體驗問題,我們改用云上對象存儲OSS服務+CDN;
- 為了解決單臺數據庫性能擴展瓶頸,我們改用云上的DRDS分布式關系數據庫;
- 為了解決大規模的車機上報而導致數據寫入延遲問題我們改用云上IOT套件+HiTSDB;
- 為了解決日常以及節假日流量高峰的問題,我們改用云上彈性伸縮服務+按量付費,以最低的成本完美解決日常及節假日流量高峰;
- 為了解決大數據存儲瓶頸以及降低大數據開發分析工作難度,我們改用云上MaxCompute + HBase;
- 為了解決運維自動化問題以及提高運維工作效率,我們改用云上codepipeine+云監控+日志服務+容器服務;
- 為了解決安全防御瓶頸,我們改用云上云盾+DDOS高防IP + web應用防火墻+堡壘機;
- 為了解決負載均衡以及網絡擴容瓶頸,我們改用云上SLB;
- 為了降低上云遷移復雜性,我們改用云上VPC虛擬專用網絡,IP地址可以和原來保持不變;
- 為了解決數據遷移的穩定性和便捷性,我們采用阿里云數據遷移工具DTS;
我們云上新的應用架構即會兼容部分老應用架構的特性,同時會采用云上新技術和云上產品來解決我們曾經的痛點和瓶頸。并且云上新架構需要滿足未來2-3年的業務發展規劃,能夠支撐千萬級用戶規模的應用系統架構。下圖為云上應用架構圖。
?
1、云上對標架構介紹
1.1安全:
安全這塊以前IDC機房的時候防范能力比較弱。為了解決安全防御瓶頸,我們改用云上云盾+DDOS高防IP + web應用防火墻+堡壘機;
可以通過配置DDoS高防IP,將攻擊流量引流到高防IP,確保源站的穩定可靠。DDoS攻擊防護峰值帶寬 20 Gbps ~ 300 Gbps 。同時,提供按天彈性付費方案,按當天攻擊規模靈活付費。
云盾Web應用防火墻可以防御SQL注入、XSS跨站腳本、常見Web服務器插件漏洞、木馬上傳、非授權核心資源訪問等OWASP常見攻擊,并過濾海量惡意CC攻擊,避免網站資產數據泄露,保障網站的安全與可用性。
關于DDOS高防IP和web應用防火墻產品介紹請詳見文章附錄第7.1&第7.2小結。
另外選擇用堡壘機來替換原來的開源堡壘機,相比開源的產品,阿里云堡壘機多了一些審計合規,高效易用,多協議支持,追溯回放等功能。
1.2負載均衡集群:
為了解決負載均衡以及網絡擴容瓶頸,我們改用云上SLB負載均衡。阿里云的SLB負責均衡提供四層(TCP協議和UDP協議)和七層(HTTP和HTTPS協議)的負載均衡服務。四層采用開源軟件LVS實現負載均衡,并根據云計算需求對其進行了個性化定制。七層采用Tengine實現負載均衡。Tengine是由淘寶網發起的Web服務器項目,它在Nginx的基礎上,針對有大訪問量的網站需求,添加了很多高級功能。更多關于阿里云負載均衡介紹請詳見文章附錄第2.2小結。
負載均衡實例規格選型:
根據當前業務量來看五百萬用戶,最高峰期間并發最大連接為50萬,推薦使用
性能保障型規格5(slb.s3.medium)最大連接數50w,每秒新建連接數5w,QPS支持3w。完全滿足當下的企業需求,如果后續業務和用戶規模繼續增長,仍然可以在線擴容到更高級別規格的SLB實例。如果未來達到千萬級用戶規模,需要大于100萬規格的實例可以聯系阿里云客戶經理開通。
?
1.3應用服務器集群:
應用服務器采用阿里云ECS云服務器,來部署應用環境。之前提到運行環境主要為JAVA環境和PHP環境,還有少部分Node.js環境。
有2種方式快速構建應用運行環境:
?
產品選型
ECS產品根據業務場景和使用場景,ECS實例可以分為多種規格族。同一業務場景下,還可以選擇新舊多種規格族。同一個規格族里,根據CPU和內存的配置,可以分為多種不同的規格。ECS實例規格定義了實例的CPU和內存的配置(包括CPU型號、主頻等)這兩個基本屬性。根據此前車聯網行業特性來看,前端web應用推薦ecs.c5.xlarge(4核8G)規格實例,而后端應用推薦ecs.g5.xlarge(4核16G)規格實例。
?
?
1.4分布式服務集群:
分布式服務集群,延用Dubbo + ZooKeeper分布式服務框架。采用7臺8核16G SSD磁盤200G ecs.c5.2xlarge規格ECS實例用于構建zookeeper集群。Zookeeper集群節點必須是奇數,因為在zookeeper集群中只要有超過一半的機器是正常工作的,那么整個集群對外就是可用的。
1.5緩存集群:
緩存集群采用阿里云數據庫Redis版,傳統自建Redis數據庫通常存在集群節點擴容復雜,管理維護難等問題。所以我們改用云上數據庫 Redis 版來替代,它具有性能卓越,彈性擴容,數據安全性高,可用性高,秒級監控,簡單易用等優勢。云數據庫Redis版支持按量付費和包年包月兩種模式,按量付費可轉為包年包月模式,反之則不可以。可根據自己的需求自主選擇更多關于云數據庫Redis介紹請詳見文章附錄第3.2小結。
1.6消息隊列集群:
消息隊列采用阿里云的消息隊列kafka服務,因為之前開源的kafka消息隊列也經常遇到各種問題,也沒有相應的能力去修復bug,選擇阿里云的消息隊列服務之后就不用擔心這些問題,因為阿里云有一支專家團隊在維護它的日常穩定運行,如出現官方bug他們有能力第一時間修復bug。更多關于阿里云消息隊列kafka介紹請詳見文章附錄第8.2小結。
1.7流計算集群:
云上流計算采用阿里云的流計算服務,相較于其他流計算產品,阿里云流計算提供一些極具競爭力的產品優勢,用戶可以充分利用阿里云流計算提供的產品優勢,方便快捷的解決自身業務實時化大數據分析的問題。產品優勢,例如強大的實時處理能力、托管的實時計算服務、良好的流式開發體驗、低廉的人力和集群成本。更多關于阿里云流計算介紹請詳見文章附錄第6.1小結。
1.8數據存儲集群:
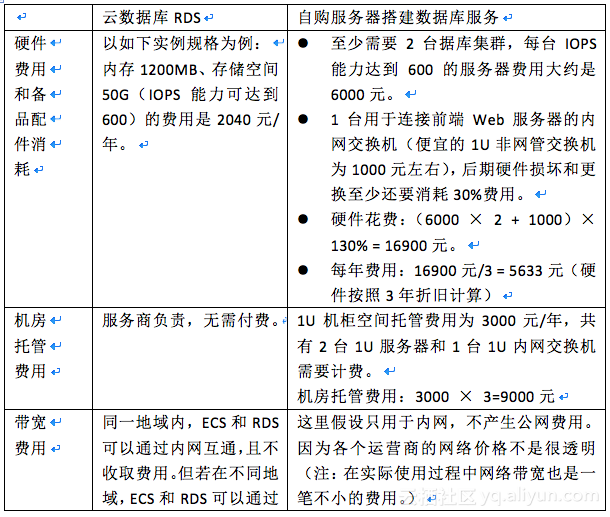
MySQL集群:采用的是阿里云數據庫RDS之MySQL版?
阿里云數據庫 MySQL 版是基于 Alibaba 的 MySQL 源碼分支,經過雙 11 高并發、大數據量的考驗,擁有優良的性能和吞吐量。除此之外,阿里云數據庫 MySQL 版還擁有經過優化的讀寫分離、數據壓縮、智能調優等高級功能。當前 RDS for MySQL 支持 5.5、5.6 和 5.7 版本。請詳見文章附錄第3.1小結。
RDS與自建數據庫對比優勢:
綜合性能對比
成本對比
HBase集群:采用的是阿里云數據庫HBase版
傳統架構中的MongoDBS用來存儲車輛上報的原始數據的,這些數據通常情況下寫多讀少,原始數據的保存可以有利于特殊情況對問題的追溯。或者是數據丟失的情況下可以用原始數據來進行彌補。原來MongoDB集群在達到一定規模之后性能出現斷崖下降,因為對MongoDB掌握不夠深,沒有正確使MongoDB導致。這里改用云上數據庫HBase版來替換原來的MongoDB集群。HBase的高并發大數據量等特性非常適合海量數據存儲,業務大屏,安全風控,搜索等場景。
HBase主要優勢有兩點:
更多關于云數據庫HBase介紹請詳見文章附錄第3.4小結。
為什么我們不自建HBase而選擇云數據庫HBase呢?云HBase和自建
?
?
Elasticsearch集群:采用阿里云的Elasticsearch
傳統自建Elasticsearch集群存在性能不足,集群節點擴容復雜,管理維護難度大等問題,因此我們改用云上Elasticsearch服務,它具有豐富的預置插件(IK Analyzer,pinyin Analyzer,smart Chinese Analysis Plugin,Mapper Attachments Type plugin等等),還包括集成X-pack插件提供企業級權限管控,實時監控等強大功能。它的特點和優勢如下:
- 分布式的實時文件存儲,每個字段都被索引并可被搜索
- 分布式的實時分析搜索引擎
- 商業版X-pack插件,提供企業級權限管控、實時系統監控等強大服務
- 可彈性擴展到上百臺服務器規模,處理PB級結構化或非結構化數據
- 支持IK analyzer插件
- Elastic官方技術支持團隊7*24小時技術支持
?
1.9文件存儲集群:
文件存儲:采用阿里云對象存儲OSS
原來自建的NFS文件系統,在擴展和訪問速度方面隨著文件數量的增加響應也越來越慢,這一塊采用阿里云的OSS+CDN解決方案,應用也需要進行小小的改造。
文件系統遷移改造方案請看2.2章節。
阿里云對象存儲服務(Object Storage Service,簡稱 OSS),是阿里云提供的海量、安全、低成本、高可靠的云存儲服務。它具有與平臺無關的RESTful API接口,能夠提供99.999999999%(11個9)的數據可靠性和99.99%的服務可用性。可以使用阿里云提供的API/SDK接口或者OSS遷移工具輕松地將海量數據移入或移出阿里云OSS。數據存儲到阿里云OSS以后,推薦選擇標準類型(Standard)的阿里云OSS服務作為移動應用、大型網站、圖片分享或熱點音視頻的主要存儲方式,也可以選擇成本更低、存儲期限更長的低頻訪問類型(Infrequent Access)和歸檔類型(Archive)的阿里云OSS服務作為不經常訪問數據的備份和歸檔。更多關于阿里云對象存儲服務OSS介紹請詳見文章附錄第4小結。
1.10 大數據計算平臺
大數據計算平臺:采用阿里云大數據計算服務智能車聯網平臺每天會采集海量車行駛數據,例如車輛發動機狀態,駕駛行為,油耗,公里數,行駛軌跡等等,我們需要對這些海量數據進行加工和分析。例如用戶每天行駛里程統計,油耗統計,用戶駕駛行為月報告等等。因初期數據量相對較小,使用Kettle進行抽取數據等工作,ETL的工作大部分在MySQL數據倉庫中完成。多種數據源使用Presto(集群)作為查詢中間鍵進行相應的數據分析。但隨著業務的瘋狂增長,數據表單表達到數億后,磁盤容量達幾百GB時,數據要求的復雜度逐步提升,使用MySQL作為基礎數據倉庫的基石已經不足以應付,常出現查詢響應時間等待過長,甚至內存崩潰導致執行失敗的情況,極大的影響了工作效率。
所以云上我們改用阿里云MaxCompute大數據計算服務來構建我們公司大數據開發和分析平臺。MaxCompute能夠為我們提供了完善的數據導入方案以及多種經典的分布式計算模型,能夠更快速的解決海量數據計算問題,有效幫助我們公司降低成本,并保障數據安全。Dataworks則提供了一站式的數據同步,數據開發,數據管理和數據運維等功能。更多關于阿里云大數據計算服務介紹請詳見文章附錄第6.2小結。
1.11運維管控集群:
之前的傳統運維,基本都是靠人肉運維,腳本運維,運維自動化程度很低,導致故障頻發,故障定位難,我們的運維同學大量時間花在了重復的升級發布工作上,花在了填坑以及解決故障上,長此以往運維同學自身發展受限,信心受挫,人員流失比例高的惡性循環的結果。我們迫切希望這種狀況可以得到較好的解決。對比之前大量采用開源的監控工具相比,大部分阿里云的產品本身就自帶web控制臺,也有一些比較實用的運維管控產品,例如云監控,堡壘機,數據管理,數據遷移,容器服務,域名等等。以前的運維痛點可以通過阿里云的運維產品可以很好的得到解決。
日志管理:采用阿里云日志服務解決日志收集,日志分析,日志搜索等問題。
阿里云日志服務是針對日志類數據的一站式服務,在阿里巴巴集團經歷大量大數據場景錘煉而成。無需開發就能快捷完成日志數據采集、消費、投遞以及查詢分析等功能,提升運維、運營效率,建立 DT 時代海量日志處理能力。具有全托管,實時性強,生態豐富,完整API等特點。
更多關于阿里云日志服務介紹請詳見文章附錄第5.7小結。
彈性擴容:采用阿里云彈性伸縮ESS,低成本解決日常以及節假日流量高峰問題。
在車聯網行業中有個比較明顯的行業特性就是早晚高峰是平時流量的3倍甚至更高,但是平常要應付這么高并發的流量意味著資源投入也要3倍以上。在傳統IDC架構中,我們通常是按照平常最高峰流量的1.2倍(1.2倍是為應對特殊情況預留的buffer)來準備相應的服務器資源,在平時資源閑置比較明顯,資源利用率不到30%,意味著平常可能100臺應用服務器就足夠了,但是為了應對高峰流量不出問題我們需要準備360臺服務器應對6個小時的高峰流量,其余18小時可能只需要100臺服務器。
為了確保系統穩定,提升用戶體驗,當時我們只能投入比平時多幾倍的服務器資源。所以在云上我們采用阿里云彈性伸縮服務,它是一種根據業務需求和策略,自動調整其彈性計算資源的管理服務。在滿足業務需求高峰增長時無縫地增加ECS實例,并在業務需求下降時自動減少ECS實例以節約成本。更多關于阿里云彈性伸縮服務介紹請詳見文章附錄第1.2小結。
域名管理:采用阿里云域名服務,一站式解決域名購買,管理,備案等問題。
以前的老萬網被阿里云收購之后,變更為阿里云域名服務,它集域名注冊、交易、解析、監控和保護為一體的綜合域名管理平臺。更多關于域名服務介紹請詳見文章附錄第5.6小結。
持續集成:傳統應用升級發布主要靠的人肉升級或者腳本升級,后來嘗試過利用開源的Jenkins+docker方式構建一個簡單的應用發布系統,我們希望到云上可以繼續保持這種發布方式,所以改用云上CodePipeline,阿里云CodePipeline是一款提供持續集成/持續交付能力,并完全兼容Jenkins的能力和使用習慣的SAAS化產品。
它無需運維,開箱即用,全量兼容Jenkins插件,支持ECS,容器服務持續部署,快速上手。更多關于codepipeline介紹請詳見文章附錄第5.9小結。
容器管理:采用阿里云容器服務,一站式解決容器生命周期管理及集群管理問題。
阿里云容器服務提供高性能可伸縮的容器應用管理服務,支持用 Docker 和 Kubernetes進行容器化應用的生命周期管理,提供多種應用發布方式和持續交付能力并支持微服務架構。容器服務簡化了容器管理集群的搭建工作,整合了阿里云虛擬化、存儲、網絡和安全能力,打造云端最佳容器運行環境。阿里云容器服務可以提供一站式容器生命周期管理以及集群管理。更多關于阿里云容器管理介紹請詳見文章附錄第5.5小結。
統一配置:采用阿里云應用配置管理,傳統IDC架構中我們的應用因為微服務架構的需要全部采用了的統一配置管理,將配置中心化管理,保存在zookeeper當中,通過一個web前端進行配置管理。應用通過本地客戶端向服務端請求配置。這樣做的好處是應用配置可以集中存放,統一配置,方便管理。但是我們的web配置管理中心提供的功能比較簡單,甚至不具備權限管理,配置快照,備份和恢復等功能。在云上我們改用阿里云的應用配置管理ACM產品。
云上應用配置管理是一款在分布式架構環境中對應用配置進行集中管理和推送的應用配置中心產品。基于該應用配置中心產品,可以在微服務、DevOps、大數據等場景下極大地減輕配置管理的工作量,增強配置管理的服務能力。阿里云ACM 是分布式系統的配置中心。通過提供配置變更、配置推送、歷史版本管理、灰度發布、配置變更審計等配置管理工具,ACM 幫助集中管理所有應用環境中的配置,降低分布式系統中管理配置的成本,并降低因錯誤的配置變更帶來可用性下降甚至發生故障的風險。更多關于阿里云應用配置管理ACM介紹請詳見文章附錄以及官方網站。
監控系統:采用阿里云監控服務,傳統IDC架構中我們的監控系統是自建的zabbix監控系統,隨著公司業務快速發展,監控項也急劇增加,由最初的500個監控項增加到3w個監控項,監控系統數據庫性能跟不上,查詢很慢,告警延遲和誤報的現象逐漸增多,監控需求越來越多樣化,定制化。傳統監控系統已經不能滿足未來業務高速發展。 所以我們云上改用云監控,云監控是一項針對阿里云資源和互聯網應用進行監控的服務。
云監控服務可用于收集獲取阿里云資源的監控指標,探測互聯網服務可用性,以及針對指標設置警報。云監控對用戶提供Dashboard、站點監控、云產品監控、自定義監控和報警服務。更多關于云監控介紹請詳見文章附錄第5.1小結。
數據可視化:采用DataV, 解決了運維大屏,監控大屏沒有UI設計問題 企業多多少少有些大屏,在公司接待參觀考察工作時展示企業形象,企業運營,以及系統運行情況等。為了提升企業形象,有必要針對數據可視化部分進行美化。阿里云的DataV 可以幫助非專業的工程師通過圖形化的界面輕松搭建具有專業水準的可視化應用,讓更多的人看到數據可視化的魅力。
DataV 提供了豐富的可視化模板,極大程度滿足會議展覽、業務監控、風險預警、地理信息分析等多種業務的展示需求。更多關于阿里云DataV數據可視化介紹請詳見文章附錄第5.2小結。
數據庫運維:采用阿里云數據管理DMS,解決數據庫運維管理問題
阿里云數據管理支持MySQL、SQL Server、PostgreSQL、MongoDB、Redis等關系型數據庫和NoSQL的數據庫管理,同時還支持Linux服務器管理。它是一種集數據管理、結構管理、訪問安全、BI圖表、數據趨勢、數據軌跡、性能與優化和服務器管理于一體的數據管理服務。更多關于阿里云數據管理DMS介紹請詳見文章附錄第5.8小結。
1.12 嘗試新產品解決老問題
問題1:海量車機設備的接入導致網絡延時高,設備管理困難,安全性差
解決方案:阿里云物聯網套件(iot套件),解決大規模車機管理,數據上報問題。
物聯網套件是阿里云專門為物聯網領域的開發人員推出的一站式設備管理平臺。性能強大的IoT Hub方便設備和云端穩定的進行雙向通信;全球多節點的部署讓全球設備都可以低延時與云端通信;多重的防護能力保障設備云端安全;功能豐富的設備管理能力幫助用戶方便進行遠程維護設備;穩定可靠的數據存儲能力方便海量設備數據存儲和實時訪問。
物聯網套件還提供規則引擎與阿里云眾多云產品打通,用戶通過規則引擎只需在web上配置規則即可實現數據采集+數據計算+數據存儲等全棧服務,靈活快速的構建物聯網應用。更多關于阿里云IOT套件介紹請詳見文章附錄。
?
問題2:車聯網大多應用場景對數據實時性要求非常高,但是目前在數據采集過程中由于數據庫寫入性能不夠,經常出現大量數據寫入延遲情況。
解決方案:阿里云高性能時間序列數據庫HiTSDB,解決海量數據寫入延遲問題。
為什么說時間序列數據庫能解決呢?
據有關機構測試發現一輛聯網汽車每小時能收集25GB數據。常規數據庫在設計之初并非處理這種規模的數據,關系型數據庫處理大數據集的效果非常糟糕;NoSQL數據庫可以很好地處理規模數據,但是它比不上一個針對時間序列數據微調過的數據庫。相比之下,時間序列數據庫(可以基于關系型數據庫或NoSQL數據庫)將時間視作一等公民,通過提高效率來處理這種大規模數據,并帶來性能的提升,包括:更高的容納率(Ingest Rates)、更快的大規模查詢(盡管有一些比其他數據庫支持更多的查詢)以及更好的數據壓縮。
阿里云高性能時間序列數據庫 (High-Performance Time Series Database , 簡稱 HiTSDB) 是一種高性能,低成本,穩定可靠的在線時序數據庫服務;提供高效讀寫,高壓縮比存儲、時序數據插值及聚合計算,廣泛應用于物聯網(IoT)設備監控系統 ,企業能源管理系統(EMS),生產安全監控系統,電力檢測系統等行業場景。
HiTSDB 提供百萬級時序數據秒級寫入,高壓縮比低成本存儲、預降采樣、插值、多維聚合計算,查詢結果可視化功能;解決由于設備采集點數量巨大,數據采集頻率高,造成的存儲成本高,寫入和查詢分析效率低的問題。后續文章會詳細介紹HiTSDB性能測試內容。更多關于HiTSDB介紹請詳見文章附錄第。
問題3:車聯網行業是典型的大數據行業,有大量的大數據分析應用場景需求,但是自建大數據平臺成本高,維護困難,大數據人才不好招。
解決方案: MaxCompute + Dataworks + 云數據庫HBase版
阿里云大數據計算服務(MaxCompute,原名 ODPS)是一種快速、完全托管的 GB/TB/PB 級數據倉庫解決方案。MaxCompute 提供了完善的數據導入方案以及多種經典的分布式計算模型,能夠更快速的解決海量數據計算問題,有效降低企業成本,并保障數據安全。
同時,DataWorks 和 MaxCompute 關系緊密,DataWorks 為 MaxCompute 提供了一站式的數據同步,任務開發,數據工作流開發,數據管理和數據運維等功能,幫助企業專注于數據價值的挖掘和探索。普通開發人員也可以勝任大數據開發任務。
云數據庫 HBase 版(ApsaraDB for HBase)是基于 Hadoop 且100%兼容HBase協議的高性能、可彈性伸縮、面向列的分布式數據庫,輕松支持PB級大數據存儲,滿足千萬級QPS高吞吐隨機讀寫場景。
阿里集團在10年開始研究HBase并使用在生產之中,目前阿里集團有10000臺左右的HBase機器,數百個集群,服務數百個業務。是一款久經沙場的大數據產品。
問題4:單機MySQL數據庫遇到IO性能瓶頸和容量擴容瓶頸,如果業務和用戶規模繼續增長將面臨單機數據庫擴展困難。
解決方案:阿里云分布式關系型數據庫服務DRDS阿里云分布式關系型數據庫服務專注于解決單機關系型數據庫擴展性問題,具備輕量(無狀態)、靈活、穩定、高效等特性,是阿里巴巴集團自主研發的中間件產品。DRDS 兼容 MySQL 協議和語法,支持分庫分表、平滑擴容、服務升降配、透明讀寫分離和分布式事務等特性,具備分布式數據庫全生命周期的運維管控能力。DRDS 主要應用場景在大規模在線數據操作上,通過貼合業務的拆分方式,將操作效率提升到極致,有效滿足用戶在線業務對關系性數據庫要求。DRDS提供了豐富的功能:分庫分表
支持 RDS/MySQL 的分庫分表,在創建分布式數據庫后,只需選擇拆分鍵,DRDS 就可以按照拆分鍵生成拆分規則,實現數據水平拆分。
透明讀寫分離
通過使用 RDS 只讀實例或者 MySQL 備機實現讀寫分離,幫助應用解決事務、只讀實例或者備機掛掉、指定主備訪問等細節問題,對應用無侵入,在 DRDS 控制臺即可完成讀寫分離相關操作。
數據存儲平滑擴容
當出現數據存儲容量和訪問量瓶頸時,DRDS 支持在線存儲容量擴展,擴容無需應用改造,擴容進度支持可視化跟蹤。
服務升降配
DRDS 實例可以通過改變資源數量實現服務能力的彈性擴展。
?
分布式運維指令集
DRDS 提供獨有分布式數據庫運維指令集,如 SHOW SLOW、TRACE、SHOW NODE 等指令,有助于快速發現和定位問題。
全局唯一數字序列
DRDS 支持分布式全局唯一且有序遞增的數字序列。滿足業務在使用分布式數據庫下對主鍵或者唯一鍵以及特定場景的需求。
數據庫賬號權限體系
DRDS 支持類單機 MySQL 賬號和權限體系,確保不同角色使用的賬號操作安全。
分布式事務
DRDS 支持分布式柔性事務,保證分布式數據庫數據一致性。
監控報警
DRDS 支持對核心資源指標和數據庫實例指標的實時監控和報警,如實例 CPU、網絡 IO、活躍線程等,幫助實時發現資源和性能瓶頸。
2、數據遷移策略
2.1 數據庫遷移策略
數據庫遷移是整個上云過程中最重要的一環,難度也最大,因為我們在遷移的時候要盡可能的減少業務本身的影響,最好是不停機不中斷現有業務。需要制定非常詳細的計劃和遷移策略:
遷移工具:推薦阿里云數據傳輸服務DTS
DTS 是阿里云提供的一種支持 RDBMS(關系型數據庫)、NoSQL、OLAP 等多種數據源之間數據交互的數據流服務。它提供了數據遷移、實時數據訂閱及數據實時同步等多種數據傳輸能力。通過數據傳輸可實現不停服數據遷移、數據異地災備、異地多活(單元化)、跨境數據同步、實時數據倉庫、查詢報表分流、緩存更新、異步消息通知等多種業務應用場景,助構建高安全、可擴展、高可用的數據架構。
DTS 支持多種數據源類型,例如:
遷移時間:推薦在業務流量最低峰時段例如每天0點至5點
遷移方法:
一般情況我們的業務數據庫都是有主備的,那么選擇從數據庫作為源數據庫對云上數據庫進行同步,這樣做的目的是為了減少對主庫的影響,有條件的話選擇單獨的從數據庫專門用作對云上數據庫進行全量同步遷移。完了之后再切換到主數據庫開啟增量數據同步(利用DTS可以輕松完成數據庫的增量同步)。這樣就可以保證線下數據庫和線上數據庫的一致性了。
2.2 文件系統遷移策略
之前采用的是自建NFS文件系統用于存儲圖片和文件。隨著文件越來越多,圖片訪問速度越來越慢,搬到云上之后,可以利用阿里云的OSS和CDN服務,構建如下的web端直傳OSS存儲方案,架構如下:
?
?
用戶的請求邏輯:
1) 用戶向應用服務器取到上傳policy和回調設置。
2) 應用服務器返回上傳policy和回調。
3) 用戶直接向OSS發送文件上傳請求。
4) 等文件數據上傳完,OSS給用戶Response前,OSS會根據用戶的回調設置,請求用戶的服務器。
5) 如果應用服務器返回成功,那么就返回用戶成功,如果應用服務器返回失敗,那么OSS也返回給用戶失敗。這樣確保了用戶上傳成功的照片,應用服務器都已經收到通知了。
6) 應用服務器給OSS返回。
7) OSS將應用服務器返回的內容返回給用戶。
?
?
利用阿里云OSS存儲代替原來的自建NFS文件系統,優勢很明顯:
?
OSS服務 配合CDN 服務一起使用,則可以加速文件存儲和訪問速度,提升用戶訪問體驗。
CDN的工作原理就是將源站的資源緩存到各地的邊緣節點服務器(CDN節點)上,用戶請求訪問和獲取資源時,就近調用CDN節點上緩存的資源。這種分布式數據傳輸方式,使得用戶請求的資源不需要都回源站獲取,從而避免網絡擁塞、分擔源站壓力,保證用戶訪問資源的速度和體驗。
使用CDN后的http請求處理流程如下圖
?
阿里云CDN在全球擁有1300+ 節點,國內完整覆蓋 34 個省級區域,大量節點位于省會等一線城市。海外覆蓋70 多個國家和地區。阿里云所有節點均接入 萬兆 網卡;具備 90 Tpbs 帶寬能力儲備。單節點存儲容量達 40 TB-1.5 PB,帶寬負載達到 40 Gbps-200 Gbps。
?
原文鏈接
本文為云棲社區原創內容,未經允許不得轉載。
總結
以上是生活随笔為你收集整理的车联网上云最佳实践(二)的全部內容,希望文章能夠幫你解決所遇到的問題。

- 上一篇: MaxCompute SQL原理解析及性
- 下一篇: Greenplum roaring bi