【机器学习】创建自己的电影推荐系统
作者 | SO_HAM
編譯 | Flin
來源 | analyticsvidhya
介紹
“每次我去看電影,不管電影是關于什么的,都很神奇。“——史蒂芬·斯皮爾伯格
每個人都喜歡電影,不分年齡、性別、種族、膚色或地理位置。通過這種神奇的媒介,我們在某種程度上彼此聯系在一起。然而,最有趣的是,我們的選擇和組合在電影偏好方面是多么獨特。
有些人喜歡特定類型的電影,比如驚悚片、愛情片或科幻片,而另一些人則喜歡主演和導演。當我們考慮到所有這些因素時,要概括一部電影并說每個人都會喜歡它是非常困難的。但盡管如此,我們仍然可以看到相似的電影受到社會特定人群的喜愛。
這就是我們作為數據科學家的作用,從觀眾的所有行為模式中提取核心信息,也從電影本身中提取信息。所以,廢話不多說,讓我們直接進入推薦系統的基礎。
什么是推薦系統?
簡單地說,推薦系統是一個過濾程序,其主要目標是預測用戶對特定領域的項目或項目的“評級”或“偏好”。在我們的例子中,這個特定于領域的項目是一部電影,因此,我們推薦系統的主要重點是在給定用戶的一些數據的情況下,過濾和預測哪些是用戶更喜歡的電影。
有哪些不同的過濾策略?
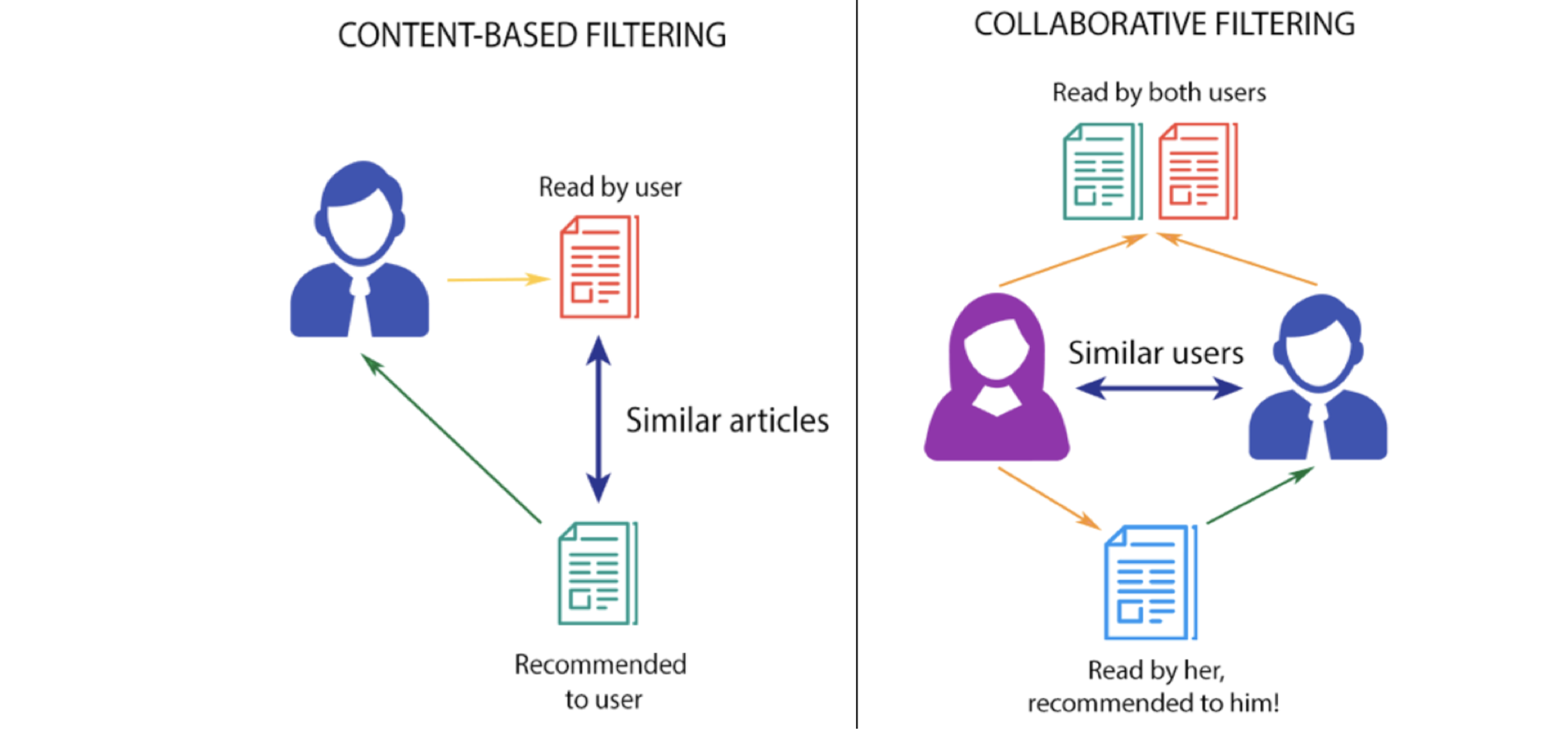
基于內容的過濾
此過濾策略基于提供的關于項目的數據。該算法會推薦與用戶過去喜歡的產品相似的產品。這種相似度(通常是余弦相似度)是根據我們擁有的關于商品的數據以及用戶過去的偏好計算出來的。
例如,如果用戶喜歡《The Prestige》這樣的電影,那么我們就可以向他推薦克里斯蒂安·貝爾(Christian Bale)的電影、驚悚片(Thriller)或者克里斯托弗·諾蘭(Christopher Nolan)導演的電影。
這里發生了什么?用戶的推薦系統檢查過去的喜好,找到這部電影《The Prestige》,然后試圖找到類似的電影,使用數據庫中的信息,如主演、導演、相關體裁的電影,制作公司等,基于這些信息找到類似于《The Prestige》的電影。
缺點
用戶很少能接觸到不同類型的產品
由于用戶不嘗試不同類型的產品,業務無法擴展。
協同過濾
該過濾策略基于用戶行為的組合,并將其與數據庫中其他用戶的行為進行比較和對比。所有用戶的歷史在該算法中扮演著重要的角色。基于內容的過濾和協同過濾的主要區別在于,協同過濾是所有用戶與項目的交互影響推薦算法,而基于內容的過濾只考慮相關用戶的數據。
協同過濾有多種實現方式,但需要把握的主要概念是,在協同過濾中,多個用戶的數據會影響推薦的結果。而且建模并不僅僅依賴于一個用戶的數據。
協同過濾算法有兩種:
基于用戶的協同過濾
這里的基本理念是找到與用戶“A”有相似偏好模式的用戶,然后推薦那些“A”還沒有遇到過的相似用戶喜歡的商品。這是通過建立一個矩陣來實現的,矩陣中列出了每個用戶根據其手頭的任務對其進行評級/查看/喜歡/點擊的項目,然后計算用戶之間的相似度得分,最后推薦相關用戶不知道但與他/她相似的用戶喜歡的項目。
例如,如果用戶A喜歡“Batman Begins”、“Justice League”和“the Avengers”,而用戶B喜歡“Batman Begins”、“Justice League”和“Thor”,那么他們的興趣是相似的,因為我們知道這些電影都屬于超級英雄類型。因此,用戶a很有可能會喜歡《雷神》,用戶B很有可能會喜歡《復仇者聯盟》。
缺點
人是浮躁的,他們的喜好是不斷變化的,因為這個算法是基于用戶相似度的,它可能會挑選出兩個用戶之間最初的相似模式,一段時間后,可能會有完全不同的偏好。
用戶比項目多很多,因此維護這么大的矩陣變得非常困難,因此需要定期重新計算。
該算法非常容易受到先令攻擊,其中包含帶有偏見的偏好模式的虛假用戶檔案被用來操縱關鍵決策。
基于項目協同過濾
這種情況下的概念是找到相似的電影,而不是相似的用戶,然后推薦與“A”過去喜歡的電影相似的電影。這是通過找到被同一用戶評價/觀看/點贊/點擊的每一對物品,然后在所有同時評價/觀看/點贊/點擊的用戶中測量那些被評價/觀看/點贊/點擊的物品的相似性,最后根據相似性分數推薦它們。
例如,我們選取兩部電影“A”和“B”,并根據這兩部電影的相似度,由所有給這兩部電影都評級過的用戶檢查它們的評級,根據給這兩部電影都評級過的用戶的評級相似度,我們會發現相似的電影。所以,如果大多數普通用戶對“A”和“B”的評價都是相似的,那么“A”和“B”很有可能是相似的,因此如果有人觀看并喜歡“A”,那么他們就應該被推薦“B”,反之亦然。
優于基于用戶的協同過濾
不像人們的喜好千變萬化,電影不會改變。
矩陣的項通常比人少很多,因此更容易維護和計算矩陣。
先令攻擊更加困難,因為電影不能偽造。
讓我們開始編寫我們自己的電影推薦系統
在這個實現中,當用戶搜索一部電影時,我們將使用我們的電影推薦系統推薦排名前10的類似電影。我們將使用基于項目的協同過濾算法。本演示中使用的數據集是movielens-small數據集。
movielens-small數據集:https://www.kaggle.com/shubhammehta21/movie-lens-small-latest-dataset
啟動并運行數據
首先,我們需要導入我們將在電影推薦系統中使用的庫。另外,我們將通過添加CSV文件的路徑來導入數據集。
import?pandas?as?pd import?numpy?as?np from?scipy.sparse?import?csr_matrix from?sklearn.neighbors?import?NearestNeighbors import?matplotlib.pyplot?as?plt import?seaborn?as?sns movies?=?pd.read_csv("../input/movie-lens-small-latest-dataset/movies.csv") ratings?=?pd.read_csv("../input/movie-lens-small-latest-dataset/ratings.csv")現在我們已經添加了數據,讓我們看看這些文件,使用dataframe.head()命令打印數據集的前5行。
讓我們來看看電影數據集:
movies.head()電影數據集有:
movieId——推薦完成后,我們會得到一個包含所有相似movieId的列表,并從這個數據集獲得每個電影的標題。
genres,體裁——這個過濾方法不需要。
評級數據集具有:
userId——對每個用戶都是唯一的。
movieId——使用這個特性,我們從電影數據集獲取電影的標題。
rating——每個用戶給所有電影的評級,使用這個我們將預測前10個類似的電影。
在這里,我們可以看到userId 1觀看了movieId 1和3,并將它們都評為4.0,但根本沒有給movieId 2打分。這個解釋很難從這個數據幀中提取出來。
因此,為了使事情更容易理解和使用,我們將創建一個新的數據幀,其中每個列將表示每個惟一的用戶id,每個行表示每個惟一的movieId。
final_dataset?=?ratings.pivot(index='movieId',columns='userId',values='rating') final_dataset.head()現在,更容易理解的是,userId 1對movieId 1和3進行了評級,但根本沒有對movieId 3、4、5進行評級(因此它們被表示為NaN),因此它們的評級數據是缺失的。
讓我們解決這個問題,并將NaN歸為0,以使算法更容易理解,同時也使數據看起來更令人舒服。
final_dataset.fillna(0,inplace=True) final_dataset.head()去除數據中的噪音
在現實世界中,評分非常少,數據點大多來自非常受歡迎的電影和高參與度的用戶。我們不希望電影被一小部分用戶評分,因為它不夠可信。同樣,只給少數幾部電影打分的用戶也不應該被考慮在內。
因此,考慮到所有這些因素和一些反復試驗,我們將通過為最終數據集添加一些過濾器來減少噪聲。
至少有10個用戶對一部電影進行了投票。
為了使一個用戶有資格,至少50部電影應該由用戶投票。
讓我們直觀地看到這些過濾器的外觀
匯總投票的用戶數量和被投票的電影數量。
no_user_voted?=?ratings.groupby('movieId')['rating'].agg('count') no_movies_voted?=?ratings.groupby('userId')['rating'].agg('count')讓我們直觀地看到以閾值10投票的用戶數量。
f,ax?=?plt.subplots(1,1,figsize=(16,4)) #?ratings['rating'].plot(kind='hist') plt.scatter(no_user_voted.index,no_user_voted,color='mediumseagreen') plt.axhline(y=10,color='r') plt.xlabel('MovieId') plt.ylabel('No.?of?users?voted') plt.show()根據閾值設置進行必要的修改。
final_dataset?=?final_dataset.loc[no_user_voted[no_user_voted?>?10].index,:]讓我們以50的閾值來可視化每個用戶的投票數量。
f,ax?=?plt.subplots(1,1,figsize=(16,4)) plt.scatter(no_movies_voted.index,no_movies_voted,color='mediumseagreen') plt.axhline(y=50,color='r') plt.xlabel('UserId') plt.ylabel('No.?of?votes?by?user') plt.show()根據閾值設置進行必要的修改。
final_dataset=final_dataset.loc[:,no_movies_voted[no_movies_voted?>?50].index] final_dataset消除稀疏
我們的final_dataset的維數是2121 * 378,其中大多數值是稀疏的。我們只使用了一個小的數據集,但是對于電影鏡頭的原始大數據集,有超過100000個特征,我們的系統可能會在將這些特征輸入到模型時耗盡計算資源。為了減少稀疏性,我們使用scipy庫中的csr_matrix函數。
我將舉個例子來說明它是如何工作的:
sample?=?np.array([[0,0,3,0,0],[4,0,0,0,2],[0,0,0,0,1]]) sparsity?=?1.0?-?(?np.count_nonzero(sample)?/?float(sample.size)?) print(sparsity)sample?=?np.array([[0,0,3,0,0],[4,0,0,0,2],[0,0,0,0,1]]) sparsity?=?1.0?-?(?np.count_nonzero(sample)?/?float(sample.size)?) print(sparsity)正如你所看到的,csr_sample中沒有稀疏值,值被分配為行和列索引。對于第0行和第2列,值是3。
應用csr_matrix函數到數據集:
csr_data?=?csr_matrix(final_dataset.values) final_dataset.reset_index(inplace=True)制作電影推薦系統模型
我們將使用KNN算法計算與余弦距離度量的相似度,這是非常快的,比皮爾遜系數更好。
knn?=?NearestNeighbors(metric='cosine',?algorithm='brute',?n_neighbors=20,?n_jobs=-1) knn.fit(csr_data)推薦函數的制作
工作原理很簡單。我們首先檢查輸入的電影名是否在數據庫中,如果在數據庫中,我們使用推薦系統查找相似的電影,并根據它們的相似距離對它們進行排序,然后只輸出與輸入電影之間的距離最高的10部電影
def?get_movie_recommendation(movie_name):n_movies_to_reccomend?=?10movie_list?=?movies[movies['title'].str.contains(movie_name)]??if?len(movie_list):????????movie_idx=?movie_list.iloc[0]['movieId']movie_idx?=?final_dataset[final_dataset['movieId']?==?movie_idx].index[0]distances?,?indices?=?knn.kneighbors(csr_data[movie_idx],n_neighbors=n_movies_to_reccomend+1)????rec_movie_indices?=?sorted(list(zip(indices.squeeze().tolist(),distances.squeeze().tolist())),key=lambda?x:?x[1])[:0:-1]recommend_frame?=?[]for?val?in?rec_movie_indices:movie_idx?=?final_dataset.iloc[val[0]]['movieId']idx?=?movies[movies['movieId']?==?movie_idx].indexrecommend_frame.append({'Title':movies.iloc[idx]['title'].values[0],'Distance':val[1]})df?=?pd.DataFrame(recommend_frame,index=range(1,n_movies_to_reccomend+1))return?dfelse:return?"No?movies?found.?Please?check?your?input"最后,我們來推薦一些電影吧!
get_movie_recommendation('Iron?Man')我個人認為結果相當不錯。所有在頂端的電影都是超級英雄或動畫電影,就像輸入電影“鋼鐵俠”一樣,是孩子們的理想選擇。
讓我們再試一個:
get_movie_recommendation('Memento')排名前十的電影都是嚴肅的、用心的電影,就像《記憶碎片》本身一樣,所以我認為這個結果也是好的。
我們的模型運行得很好——一個基于用戶行為的電影推薦系統。因此,我們在此總結我們的協同過濾。你可以在這里得到完整的實現代碼。
https://github.com/So-ham/Movie-Recommendation-System
原文鏈接:https://www.analyticsvidhya.com/blog/2020/create-your-own-movie-movie-recommendation-system/
往期精彩回顧適合初學者入門人工智能的路線及資料下載機器學習及深度學習筆記等資料打印機器學習在線手冊深度學習筆記專輯《統計學習方法》的代碼復現專輯 AI基礎下載機器學習的數學基礎專輯溫州大學《機器學習課程》視頻 本站qq群851320808,加入微信群請掃碼:總結
以上是生活随笔為你收集整理的【机器学习】创建自己的电影推荐系统的全部內容,希望文章能夠幫你解決所遇到的問題。

- 上一篇: Win10系统如何查看声卡ID
- 下一篇: 技术员联盟win11旗舰版64位系统v2