【机器学习】使用集成学习回归器改善预测模型的得分
作者 | SHYAM2106
編譯 | Flin
來源 | analyticsvidhya
介紹
集成的一般原則是將各種模型的預(yù)測與給定的學(xué)習(xí)算法相結(jié)合,以提高單個模型的魯棒性。
“整體大于部分的總和。” –亞里斯多德
換句話說,將各個部分連接在一起以形成一個實體時,它們的價值要大于將各個部分分開的價值。
上面的說法更適合堆疊,因為我們結(jié)合了不同的模型以獲得更好的性能。在本文中,我們將討論堆疊以及如何創(chuàng)建自己的堆棧回歸器。
堆疊是什么意思?
集成學(xué)習(xí)是機器學(xué)習(xí)從業(yè)人員廣泛使用的一種技術(shù),它結(jié)合了不同模型的技能,可以根據(jù)給定的數(shù)據(jù)進行預(yù)測。我們正在使用它來結(jié)合多種算法的最佳性能,這些算法可以提供比單個回歸器更穩(wěn)定的預(yù)測,并且方差很小。
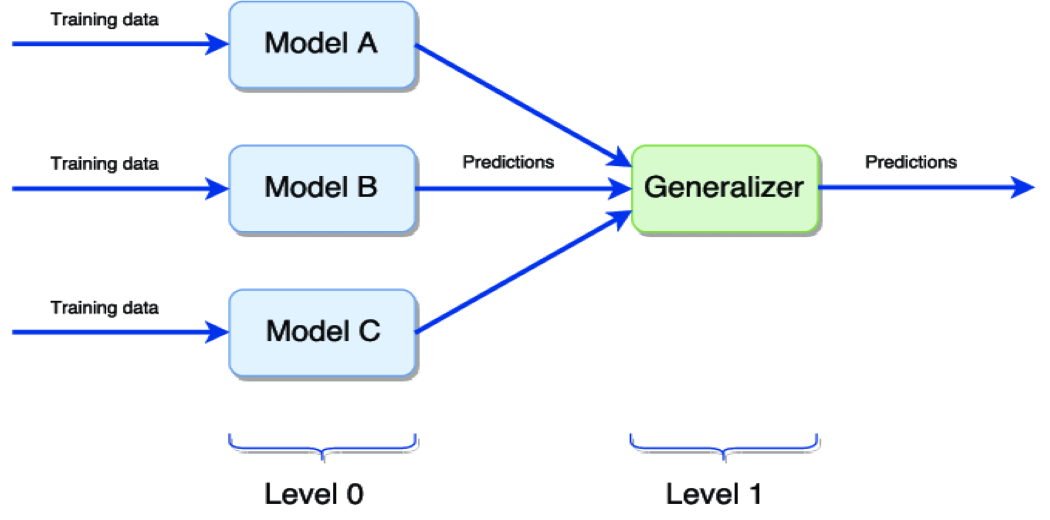
上圖表示模型的簡單堆疊:
Level 0 在同一數(shù)據(jù)集上訓(xùn)練不同的模型,然后進行預(yù)測。
Level 1 概括由不同模型做出的預(yù)測以獲得最終輸出。
泛化器最常用的方法是取所有0級模型預(yù)測的平均值,以獲得最終輸出。
創(chuàng)建自己的堆棧回歸器
我們將采用 Kaggle著名的房價預(yù)測數(shù)據(jù)集。目的是根據(jù)數(shù)據(jù)集中存在的幾種特征來預(yù)測房價。
房價預(yù)測數(shù)據(jù)集:https://www.kaggle.com/c/house-prices-advanced-regression-techniques
基礎(chǔ)模型
我們將使用k-fold交叉驗證來訓(xùn)練不同的基礎(chǔ)模型,并查看給定數(shù)據(jù)集中所有模型的性能(RMSE)。
下面的函數(shù) rmse_cv 用于在創(chuàng)建數(shù)據(jù)的5倍中訓(xùn)練所有單個模型,并根據(jù)與實際預(yù)測相比的非折疊預(yù)測返回該模型的RMSE分數(shù)。
#Validation?function n_folds?=?5def?rmse_cv(model):kf?=?KFold(n_folds,?shuffle=True,?random_state=42).get_n_splits(train.values)rmse=?np.sqrt(-cross_val_score(model,?train.values,?y_train,?scoring="neg_mean_squared_error",?cv?=?kf))return(rmse)注意:在訓(xùn)練基礎(chǔ)模型之前,已完成所有數(shù)據(jù)預(yù)處理技術(shù)。
Lasso
lasso?=?Lasso(alpha?=0.0005) rmse_cv(lasso)Lasso?score:?0.1115ElasticNet
ENet?=?ElasticNet(alpha=0.0005,?l1_ratio=.9) rmse_cv(ENet)ElasticNet?Score:?0.1116Kernel Ridge Regression
KRR?=?KernelRidge(alpha=0.6,?kernel='polynomial',?degree=2,?coef0=2.5) rmse_cv(KRR)Kernel?Ridge?Score:?0.1153Gradient Boosting
GBoost?=?GradientBoostingRegressor(n_estimators=3000,?learning_rate=0.05,max_depth=4,max_features='sqrt',min_samples_leaf=15,?min_samples_split=10,loss='huber') rmse_cv(GBoost)Gradient?Boosting?Score:?0.1177XGB Regressor
model_xgb?=?xgb.XGBRegressor(colsample_bytree=0.4603,?gamma=0.0468,?learning_rate=0.05,?max_depth=3,?min_child_weight=1.7817,?n_estimators=2200,reg_alpha=0.4640,?reg_lambda=0.8571,subsample=0.5213,?silent=1,random_state?=7,?nthread?=?-1) rmse_cv(model_xgb)XGBoost?Score:?0.1161LightGBM
model_lgb?=?lgb.LGBMRegressor(objective='regression',num_leaves=5,learning_rate=0.05,?n_estimators=720,max_bin?=?55,?bagging_fraction?=?0.8,bagging_freq?=?5,?feature_fraction?=?0.2319,feature_fraction_seed=9,?bagging_seed=9,min_data_in_leaf?=6,?min_sum_hessian_in_leaf?=?11) rmse_cv(model_lgb)LGBM?Score:?0.1157類型1:最簡單的堆棧回歸方法:平均基礎(chǔ)模型
我們從平均基礎(chǔ)模型的簡單方法開始。建立一個新類,以通過我們的模型擴展scikit-learn,并利用封裝和代碼重用。
平均基礎(chǔ)模型類別
from?sklearn.base?import?BaseEstimator,?TransformerMixin,?RegressorMixin,?clone class?AveragingModels(BaseEstimator,?RegressorMixin,?TransformerMixin):def?__init__(self,?models):self.models?=?models#?we?define?clones?of?the?original?models?to?fit?the?data?indef?fit(self,?X,?y):self.models_?=?[clone(x)?for?x?in?self.models]#?Train?cloned?base?modelsfor?model?in?self.models_:model.fit(X,?y)return?self#Now?we?do?the?predictions?for?cloned?models?and?average?themdef?predict(self,?X):predictions?=?np.column_stack([model.predict(X)?for?model?in?self.models_])return?np.mean(predictions,?axis=1)fit()?:此方法將克隆作為參數(shù)傳遞的所有基礎(chǔ)模型,然后在整個數(shù)據(jù)集中訓(xùn)練克隆的模型。
predict()?:所有克隆的模型將進行預(yù)測,并使用“np.column_stack”對預(yù)測進行列堆疊,然后將計算并返回該預(yù)測的平均值。
np.column_stack:https://numpy.org/doc/stable/reference/generated/numpy.column_stack.html
averaged_models?=?AveragingModels(models?=?(ENet,?GBoost,?KRR,?lasso)) score?=?rmsle_cv(averaged_models) print("?Averaged?base?models?score:?{:.4f}n".format(score.mean()))Averaged?base?models?score:?0.1091哇!即使簡單地取所有基礎(chǔ)模型的平均預(yù)測值,也能獲得不錯的RMSE分數(shù)。
類型2:添加元模型
在這種方法中,我們將訓(xùn)練所有基礎(chǔ)模型,并將基礎(chǔ)模型的預(yù)測(失疊預(yù)測)用作元模型的訓(xùn)練特征。
元模型用于在作為特征的基礎(chǔ)模型預(yù)測與作為目標變量的實際預(yù)測之間找到模式。
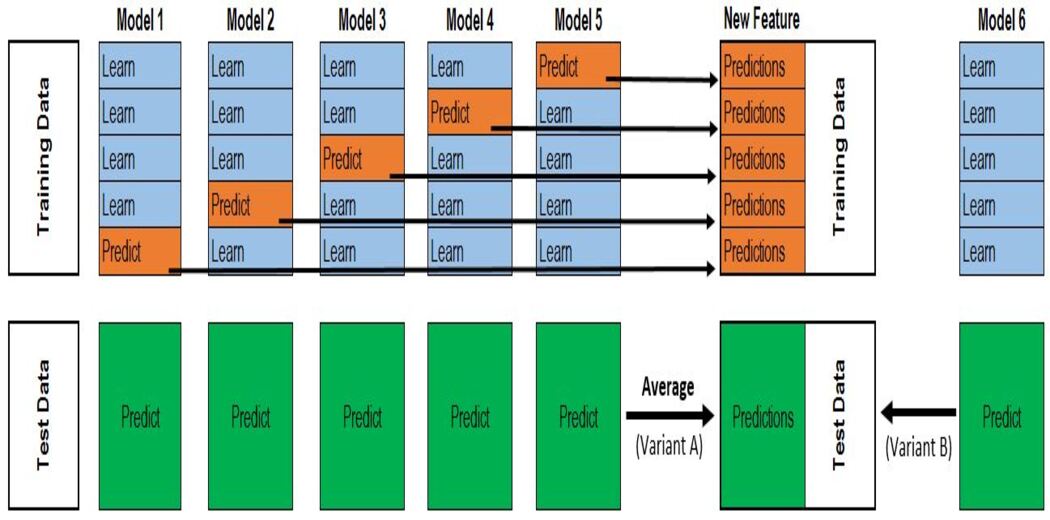
步驟:
1.將數(shù)據(jù)分為2組訓(xùn)練和驗證集。
2.在訓(xùn)練數(shù)據(jù)中訓(xùn)練所有基礎(chǔ)模型。
3.在驗證數(shù)據(jù)集上測試基礎(chǔ)模型,并存儲預(yù)測(失疊預(yù)測)。
4.使用基礎(chǔ)模型做出的失疊預(yù)測作為輸入特征,并使用正確的輸出作為目標變量來訓(xùn)練元模型。
前三個步驟將根據(jù)k的值針對k折進行迭代。如果k = 5,那么我們將在4折上訓(xùn)練模型,并在驗證集(第5折)上進行預(yù)測。重復(fù)此步驟k次(此處,k = 5)可得出整個數(shù)據(jù)集的失疊預(yù)測。這將對所有的基礎(chǔ)模型進行。
然后,將使用所有模型的超預(yù)期作為X并將原始目標變量作為y來訓(xùn)練元模型。該元模型的預(yù)測將被視為最終預(yù)測。
class?StackingAveragedModels(BaseEstimator,?RegressorMixin,?TransformerMixin):def?__init__(self,?base_models,?meta_model,?n_folds=5):self.base_models?=?base_modelsself.meta_model?=?meta_modelself.n_folds?=?n_folds#?We?again?fit?the?data?on?clones?of?the?original?modelsdef?fit(self,?X,?y):self.base_models_?=?[list()?for?x?in?self.base_models]self.meta_model_?=?clone(self.meta_model)kfold?=?KFold(n_splits=self.n_folds,?shuffle=True,?random_state=156)#?Train?cloned?base?models?then?create?out-of-fold?predictions#?that?are?needed?to?train?the?cloned?meta-modelout_of_fold_predictions?=?np.zeros((X.shape[0],?len(self.base_models)))for?i,?model?in?enumerate(self.base_models):for?train_index,?holdout_index?in?kfold.split(X,?y):instance?=?clone(model)self.base_models_[i].append(instance)instance.fit(X[train_index],?y[train_index])y_pred?=?instance.predict(X[holdout_index])out_of_fold_predictions[holdout_index,?i]?=?y_pred#?Now?train?the?cloned??meta-model?using?the?out-of-fold?predictions?as?new?featureself.meta_model_.fit(out_of_fold_predictions,?y)return?self#Do?the?predictions?of?all?base?models?on?the?test?data?and?use?the?averaged?predictions?as?#meta-features?for?the?final?prediction?which?is?done?by?the?meta-modeldef?predict(self,?X):meta_features?=?np.column_stack([np.column_stack([model.predict(X)?for?model?in?base_models]).mean(axis=1)for?base_models?in?self.base_models_?])return?self.meta_model_.predict(meta_features)fit() :克隆基礎(chǔ)模型和元模型,以5倍交叉驗證對基礎(chǔ)模型進行訓(xùn)練,并存儲非折疊預(yù)測。然后使用超出范圍的預(yù)測來訓(xùn)練元模型。
Forecast() :X的基礎(chǔ)模型預(yù)測將按列堆疊,然后用作元模型進行預(yù)測的輸入。
stacked_averaged_models?=?StackingAveragedModels(base_models?=?(ENet,?GBoost,?KRR),meta_model?=?lasso)score?=?rmsle_cv(stacked_averaged_models) print("Stacking?Averaged?models?score:?{:.4f}".format(score.mean()))Stacking?Averaged?models?score:?0.1085哇… !!! 通過使用元學(xué)習(xí)器,我們再次獲得了更好的分數(shù)。
結(jié)論
上面的堆疊方法也可以在稍作更改的情況下用于分類任務(wù)。除了對基礎(chǔ)模型預(yù)測進行平均以外,我們還可以對所有模型預(yù)測進行投票,并且可以將投票最高的類別作為輸出。
下述鏈接顯示了使用上述方法從數(shù)據(jù)預(yù)處理到模型構(gòu)建的示例。
https://www.kaggle.com/shyam21/stacked-regression-public-leaderboard-23-09
往期精彩回顧適合初學(xué)者入門人工智能的路線及資料下載機器學(xué)習(xí)及深度學(xué)習(xí)筆記等資料打印機器學(xué)習(xí)在線手冊深度學(xué)習(xí)筆記專輯《統(tǒng)計學(xué)習(xí)方法》的代碼復(fù)現(xiàn)專輯 AI基礎(chǔ)下載機器學(xué)習(xí)的數(shù)學(xué)基礎(chǔ)專輯溫州大學(xué)《機器學(xué)習(xí)課程》視頻 本站qq群851320808,加入微信群請掃碼:總結(jié)
以上是生活随笔為你收集整理的【机器学习】使用集成学习回归器改善预测模型的得分的全部內(nèi)容,希望文章能夠幫你解決所遇到的問題。

- 上一篇: win7压缩文件夹怎么压缩到最小
- 下一篇: 优酷下载的视频保存在哪里