14.程序员常用10种算法
1、二分查找算法(非遞歸)
簡單介紹
二分查找法只適用于從有序的數列中進行查找(比如數字和字母等),將數列排序后再進行查找
二分查找法的運行時間為對數時間O(㏒?n) ,即查找到需要的目標位置最多只需要㏒?n步,假設從[0,99]的隊列(100個數,即n=100)中尋到目標數30,則需要查找步數為㏒?100 , 即最多需要查找7次( 2^6 < 100 < 2^7)
代碼實現
- 數組 {1,3, 8, 10, 11, 67, 100}, 編程實現二分查找, 要求使用非遞歸的方式完成.
2、分治算法
簡單介紹
1)分治法是一種很重要的算法。字面上的解釋是“分而治之”,就是把一個復雜的問題分成兩個或更多的相同或相似的子問題,再把子問題分成更小的子問題……直到最后子問題可以簡單的直接求解,原問題的解即子問題的解的合并。這個技巧是很多高效算法的基礎,如排序算法(快速排序,歸并排序),傅立葉變換(快速傅立葉變換)……
? 二分搜索 大整數乘法 棋盤覆蓋 合并排序 快速排序
? 線性時間選擇 最接近點對問題 循環賽日程表 漢諾塔
基本步驟
1)分解:將原問題分解為若干個規模較小,相互獨立,與原問題形式相同的子問題
2)解決:若子問題規模較小而容易被解決則直接解,否則遞歸地解各個子問題
3)合并:將各個子問題的解合并為原問題的解。
分治(Divide-and-Conquer§)算法設計模式如下
if |P|≤n0then return(ADHOC(P))//將P分解為較小的子問題 P1 ,P2 ,…,Pkfor i←1 to kdo yi ← Divide-and-Conquer(Pi) 遞歸解決PiT ← MERGE(y1,y2,…,yk) 合并子問題return(T)其中|P|表示問題P的規模;n0為一閾值,表示當問題P的規模不超過n0時,問題已容易直接解出,不必再繼續分解。ADHOC§是該分治法中的基本子算法,用于直接解小規模的問題P。因此,當P的規模不超過n0時直接用算法ADHOC§求解。算法MERGE(y1,y2,…,yk)是該分治法中的合并子算法,用于將P的子問題P1 ,P2 ,…,Pk的相應的解y1,y2,…,yk合并為P的解。
代碼實現
?漢諾塔的傳說
漢諾塔:漢諾塔(又稱河內塔)問題是源于印度一個古老傳說的益智玩具。大梵天創造世界的時候做了三根金剛石柱子,在一根柱子上從下往上按照大小順序摞著64片黃金圓盤。大梵天命令婆羅門把圓盤從下面開始按大小順序重新擺放在另一根柱子上。并且規定,在小圓盤上不能放大圓盤,在三根柱子之間一次只能移動一個圓盤。
假如每秒鐘一次,共需多長時間呢?移完這些金片需要5845.54億年以上,太陽系的預期壽命據說也就是數百億年。真的過了5845.54億年,地球上的一切生命,連同梵塔、廟宇等,都早已經灰飛煙滅。
思路分析:
如果是有一個盤, A->C
? 如果我們有 n >= 2 情況,我們總是可以看做是兩個盤 1.最下邊的盤 2. 上面的盤
先把 最上面的盤 A->B
把最下邊的盤 A->C
把B塔的所有盤 從 B->C
3、動態規劃算法
簡單介紹
動態規劃(Dynamic Programming)算法的核心思想是:將大問題劃分為小問題進行解決,從而一步步獲取最優解的處理算法
動態規劃算法與分治算法類似,其基本思想也是將待求解問題分解成若干個子問題,先求解子問題,然后從這些子問題的解得到原問題的解。
與分治法不同的是,適合于用動態規劃求解的問題,經分解得到子問題往往不是互相獨立的。 ( 即下一個子階段的求解是建立在上一個子階段的解的基礎上,進行進一步的求解 )
動態規劃可以通過填表的方式來逐步推進,得到最優解.
應用場景
1. 要求達到的目標為裝入的背包的總價值最大,并且重量不超出 2. 要求裝入的物品不能重復 3. 思路分析和圖解背包問題主要是指一個給定容量的背包、若干具有一定價值和重量的物品,如何選擇物品放入背包使物品的價值最大。其中又分01背包和完全背包(完全背包指的是:每種物品都有無限件可用)這里的問題屬于01背包,即每個物品最多放一個。而無限背包可以轉化為01背包 4. 算法的主要思想,利用動態規劃來解決。每次遍歷到的第i個物品,根據w[i]和v[i]來確定是否需要將該物品放入背包中。即對于給定的n個物品,設v[i]、w[i]分別為第i個物品的價值和重量,C為背包的容量。再令v[i][j]表示在前i個物品中能夠裝入容量為j的背包中的最大價值。則我們有下面的結果:1. v[i][0]=v[0][j]=0; //表示 填入表 第一行和第一列是02. 當w[i]> j 時:v[i][j]=v[i-1][j] // 當準備加入新增的商品的容量大于 當前背包的容量時,就直接使用上一個單元格的裝入策略3. 當j>=w[i]時: v[i][j]=max{v[i-1][j], v[i]+v[i-1][j-w[i]]} - 當準備加入的新增的商品的容量小于等于當前背包的容量,- 裝入的方式:- v[i-1][j]: 就是上一個單元格的裝入的最大值- v[i] : 表示當前商品的價值 - v[i-1][j-w[i]] : 裝入i-1商品,到剩余空間j-w[i]的最大值- 當j>=w[i]時: vi=max{vi-1, v[i]+vi-1]} :```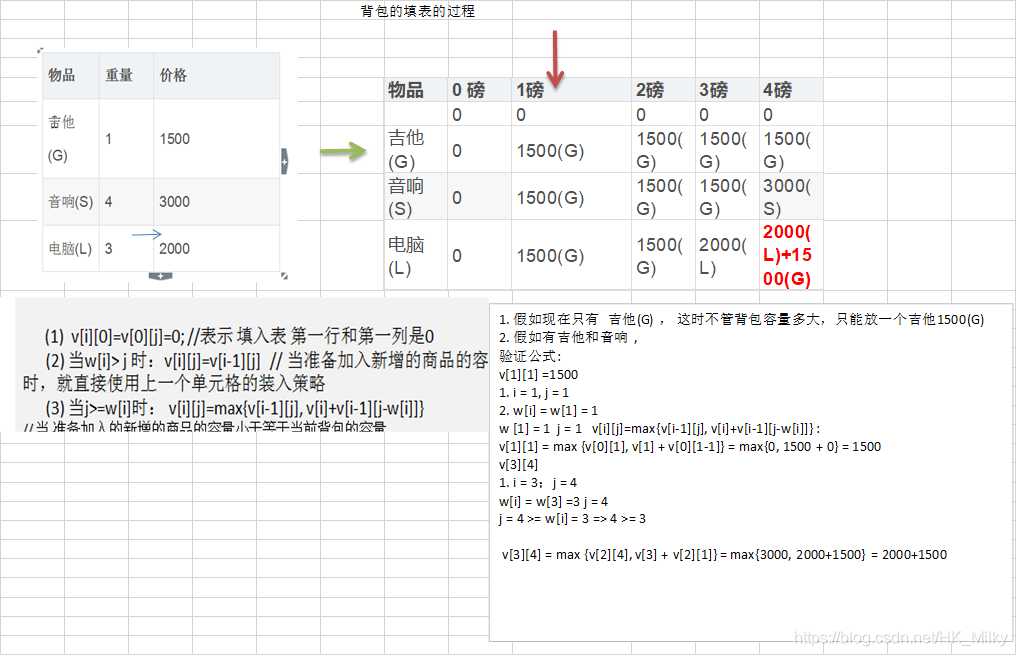 ## 代碼展示```javapackage demo03;//動態規劃算法 背包問題public class KnapsackProblem {public static void main(String[] args) {int[] w = {1, 4, 3};//物品的重量int[] val = {1500, 3000, 2000};//物品的價值 這里的val[i],就是v[i]int m = 4;//背包的容量int n = val.length;//物品的個數//創建二維數組//v[i][j],表示在前i個物品中能夠轉入容量為j的背包中的最大價值int[][] v = new int[n + 1][m + 1];//為了記錄放入商品的情況,我們定義一個二維數組int[][] path = new int[n + 1][m + 1];//初始化第一行和第一列,這里在本程序中可以不去處理,因為默認就是0for (int i = 0; i < v.length; i++) {v[i][0] = 0;//將第一列設置為0}for (int i = 0; i < v[0].length; i++) {v[0][i] = 0;//將第一行設置為0}//根據前面的公式,動態規劃處理for (int i = 1; i < v.length; i++) { //不處理第一行 i是從1開始的for (int j = 1; j < v[0].length; j++) { //不處理第一列 j是從1開始的//公式if (w[i - 1] > j) { //因為我們程序i 是從1開始的,因此我們原來公式中 w[i] 要修改為 w[i-1]v[i][j] = v[i - 1][j];} else {// 因為i 是從1開始的//v[i][j]=Math.max(v[i-1][j],val[i-1]+v[i-1][j-w[i-1]]);//為了記錄商品存放到背包的情況,不能直接使用上面的公式,要使用if-else來體現公式if (v[i - 1][j] < val[i - 1] + v[i - 1][j - w[i - 1]]) {v[i][j] = val[i - 1] + v[i - 1][j - w[i - 1]];//把當前的情況記錄到path中path[i][j] = 1;} else {v[i][j] = v[i - 1][j];}}}}//輸出一下 v,看看目前的情況for (int i = 0; i < v.length; i++) {for (int j = 0; j < v[0].length; j++) {System.out.print(v[i][j] + " ");}System.out.println();}//輸出最后我們是放入了那些商品//遍歷 path 這樣輸出會把所有的情況都得到,其實我們只需要最后放入的// for (int i = 0; i < path.length; i++) {// for (int j = 0; j < path[i].length; j++) {// if (path[i][j]==1) {// System.out.printf("第%d個商品放入到背包\n", i);// }// }// }int i = path.length - 1;//行的最大下標int j = path[0].length - 1; //列的最大下標while (i > 0 && j > 0) { //從path的最后開始找if (path[i][j] == 1) {System.out.printf("第%d個商品放入到背包\n", i);j -= w[i - 1];}i--;}}}4、KMP算法
問題展示
字符串匹配問題::
有一個字符串 str1= ““硅硅谷 尚硅谷你尚硅 尚硅谷你尚硅谷你尚硅你好””,和一個子串 str2=“尚硅谷你尚硅你”
現在要判斷 str1 是否含有 str2, 如果存在,就返回第一次出現的位置, 如果沒有,則返回-1
暴力匹配算法
思路分析
如果用暴力匹配的思路,并假設現在str1匹配到 i 位置,子串str2匹配到 j 位置,則有:1. 如果當前字符匹配成功(即str1[i] == str2[j]),則i++,j++,繼續匹配下一個字符2. 如果失配(即str1[i]! = str2[j]),令i = i - (j - 1),j = 0。相當于每次匹配失敗時,i 回溯,j 被置為0。3. 用暴力方法解決的話就會有大量的回溯,每次只移動一位,若是不匹配,移動到下一位接著判斷,浪費了大量的時間。(不可行!)代碼實現
package demo04;public class ViolenceMatch {public static void main(String[] args) {//測試暴力匹配算法String s1="aaa d d da adad acar";String s2="d da";int index = violenceMatch(s1, s2);System.out.println(index);}//暴力匹配算法實現public static int violenceMatch(String str1, String str2) {char[] s1 = str1.toCharArray();char[] s2 = str2.toCharArray();int s1Length = s1.length;int s2Length = s2.length;int i = 0; //i索引指向s1int j = 0; //j索引指向s2while (i < s1Length && j < s2Length) {//保證匹配時,不越界if (s1[i]==s2[j]){ //匹配成功i++;j++;}else {//匹配失敗 (即 str1[i] != str2[j]),令 i=i-(j-1),j=0i=i-(j-1);j=0;}}//判斷是否匹配成功if (j==s2Length){return i-j;}else {return -1;}}}KMP算法
-
KMP是一個解決模式串在文本串是否出現過,如果出現過,最早出現的位置的經典算法
-
Knuth-Morris-Pratt 字符串查找算法,簡稱為 “KMP算法”,常用于在一個文本串S內查找一個模式串P 的出現位置,這個算法由Donald Knuth、Vaughan Pratt、James H. Morris三人于1977年聯合發表,故取這3人的姓氏命名此算法.
-
KMP方法算法就利用之前判斷過信息,通過一個next數組,保存模式串中前后最長公共子序列的長度,每次回溯時,通過next數組找到,前面匹配過的位置,省去了大量的計算時間
(詳細了解KMP算法的運行【】涉及底層)參考資料:https://www.cnblogs.com/ZuoAndFutureGirl/p/9028287.html
KMP運行過程
舉例來說,有一個字符串 Str1 = “BBC ABCDAB ABCDABCDABDE”,判斷,里面是否包含另一個字符串 Str2 = “ABCDABD”? 1.首先,用Str1的第一個字符和Str2的第一個字符去比較,不符合,關鍵詞向后移動一位 2.重復第一步,還是不符合,再后移 3.一直重復,直到Str1有一個字符與Str2的第一個字符符合為止 4.接著比較字符串和搜索詞的下一個字符,還是符合。 5.遇到Str1有一個字符與Str2對應的字符不符合。 6.這時候,想到的是繼續遍歷Str1的下一個字符,重復第1步。(其實是很不明智的,因為此時BCD已經比較過了,沒有必要再做重復的工作,一個基本事實是,當空格與D不匹配時,你其實知道前面六個字符是”ABCDAB”。KMP 算法的想法是,設法利用這個已知信息,不要把”搜索位置”移回已經比較過的位置,繼續把它向后移,這樣就提高了效率。) 7.怎么做到把剛剛重復的步驟省略掉?可以對Str2計算出一張《部分匹配表》,這張表的產生在后面介紹 8.已知空格與D不匹配時,前面六個字符”ABCDAB”是匹配的。查表可知,最后一個匹配字符B對應的”部分匹配值”為2,因此按照下面的公式算出向后移動的位數: 移動位數 = 已匹配的字符數 - 對應的部分匹配值 因為 6 - 2 等于4,所以將搜索詞向后移動 4 位。 9.因為空格與C不匹配,搜索詞還要繼續往后移。這時,已匹配的字符數為2(”AB”),對應的”部分匹配值”為0。所以,移動位數 = 2 - 0,結果為 2,于是將搜索詞向后移 2 位。 10.因為空格與A不匹配,繼續后移一位。 11.逐位比較,直到發現C與D不匹配。于是,移動位數 = 6 - 2,繼續將搜索詞向后移動 4 位。 12.逐位比較,直到搜索詞的最后一位,發現完全匹配,于是搜索完成。如果還要繼續搜索(即找出全部匹配),移動位數 = 7 - 0,再將搜索詞向后移動 7 位,這里就不再重復了。 13.介紹《部分匹配表》怎么產生的 先介紹前綴,后綴是什么 “部分匹配值”就是”前綴”和”后綴”的最長的共有元素的長度。以”ABCDABD”為例, -”A”的前綴和后綴都為空集,共有元素的長度為0; -”AB”的前綴為[A],后綴為[B],共有元素的長度為0; -”ABC”的前綴為[A, AB],后綴為[BC, C],共有元素的長度0; -”ABCD”的前綴為[A, AB, ABC],后綴為[BCD, CD, D],共有元素的長度為0; -”ABCDA”的前綴為[A, AB, ABC, ABCD],后綴為[BCDA, CDA, DA, A],共有元素為”A”,長度為1; -”ABCDAB”的前綴為[A, AB, ABC, ABCD, ABCDA],后綴為[BCDAB, CDAB, DAB, AB, B],共有元素為”AB”,長度為2; -”ABCDABD”的前綴為[A, AB, ABC, ABCD, ABCDA, ABCDAB],后綴為[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的長度為0。14.”部分匹配”的實質是,有時候,字符串頭部和尾部會有重復。比如,”ABCDAB”之中有兩個”AB”,那么它的”部分匹配值”就是2(”AB”的長度)。搜索詞移動的時候,第一個”AB”向后移動 4 位(字符串長度-部分匹配值),就可以來到第二個”AB”的位置。 ~~完畢~~代碼展示
package demo05;import java.util.Arrays;public class KMPAlgonithm {public static void main(String[] args) {String str1="BBC ABCDAB ABCDABCDABDE";String str2="ABCDABD";int[] next=kmpNext(str2);System.out.println(Arrays.toString(next));int index=kmpSearch(str1,str2,next);System.out.println(index);}/*** 寫出kmp搜索算法* @param str1 源字符串* @param str2 子串* @param next 部分匹配表,是子串對應的部分匹配表* @return 如果是 -1就是沒有匹配到,否則返回第一個匹配位置*/public static int kmpSearch(String str1,String str2,int[] next){//遍歷for (int i = 0,j=0; i < str1.length(); i++) {//需要考慮str1.charAt(i)!=str2.charAt(j),去調整 j的大小//kmp算法核心點 要了解如何運行,得看底層while (j>0 && str1.charAt(i) != str2.charAt(j)){j=next[j-1];}if (str1.charAt(i)==str2.charAt(j)){j++;}if (j==str2.length()){ //找到了return i-j+1;}}return -1;}//獲取到一個字符串(子串) 的部分匹配值public static int[] kmpNext(String dest){//創建一個next 數組保存部分匹配值int[] next=new int[dest.length()];next[0]=0;//如果字符串是長度為1,部分匹配值就是 0for (int i = 1,j=0; i < dest.length(); i++) {//當 dest.charAt(i)!=dest.charAt(j),我們需要從next[j-1]獲取新的j//直到我們發現 有 dest.charAt(i) == dest.charAt(j)成立才退出//這是kmp算法的核心點 要了解如何運行,得看底層while (j>0 && dest.charAt(i) != dest.charAt(j)){j=next[j-1];}//當 dest.charAt(i)==dest.charAt(j) 滿足時,部分匹配值就是 +1if (dest.charAt(i)==dest.charAt(j)){j++;}next[i]=j;}return next;} }5、貪心算法
簡單介紹
貪婪算法(貪心算法)是指在對問題進行求解時,在每一步選擇中都采取最好或者最優(即最有利)的選擇,從而希望能夠導致結果是最好或者最優的算法
貪婪算法所得到的結果不一定是最優的結果(有時候會是最優解),但是都是相對近似(接近)最優解的結果
應用場景
1)假設存在如下表的需要付費的廣播臺,以及廣播臺信號可以覆蓋的地區。 如何選擇最少的廣播臺,讓所有的地區都可以接收到信號
| K1 | “北京”, “上海”, “天津” |
| K2 | “廣州”, “北京”, “深圳” |
| K3 | “成都”, “上海”, “杭州” |
| K4 | “上海”, “天津” |
| K5 | “杭州”, “大連” |
思路分析
- 窮舉法
- 使用窮舉法實現,列出每個可能的廣播臺的集合,這被稱為冪集。假設總的有n個廣播臺,則廣播臺的組合總共有2? -1 個,假設每秒可以計算10個子集, 如圖:
| 5 | 32 | 3.2秒 |
| 10 | 1024 | 102.4秒 |
| 32 | 4294967296 | 13.6年 |
| 100 | 1.26*1003o | 4x1023年 |
-
?貪婪算法,效率高:
-
目前并沒有算法可以快速計算得到準備的值, 使用貪婪算法,則可以得到非常接近的解,并且效率高。選擇策略上,因為需要覆蓋全部地區的最小集合:
-
遍歷所有的廣播電臺, 找到一個覆蓋了最多未覆蓋的地區的電臺(此電臺可能包含一些已覆蓋的地區,但沒有關系)
-
將這個電臺加入到一個集合中(比如ArrayList), 想辦法把該電臺覆蓋的地區在下次比較時去掉。
-
重復第1步直到覆蓋了全部的地區
注意事項:
- 貪婪算法所得到的結果不一定是最優的結果(有時候會是最優解),但是都是相對近似(接近)最優解的結果
- *比如上題的**算法選出的是K1, K2, K3, K5,符合覆蓋了全部的地區
- 但是我們發現 K2, K3,K4,K5 也可以覆蓋全部地區,如果K2 的使用成本低于K1,那么我們上題的 K1, K2, K3, K5 雖然是滿足條件,但是并不是最優的.
代碼展示
package demo06;import java.util.ArrayList; import java.util.HashMap; import java.util.HashSet; import java.util.Map;public class GreedyAlgorithm {public static void main(String[] args) {//創建廣播電臺,放入到Map中Map<String, HashSet<String>> broadcasts = new HashMap<>();//將各個廣播電臺放入到broadcastsHashSet<String> hashSet1=new HashSet<>();hashSet1.add("北京");hashSet1.add("上海");hashSet1.add("天津");HashSet<String> hashSet2=new HashSet<>();hashSet2.add("廣州");hashSet2.add("北京");hashSet2.add("深圳");HashSet<String> hashSet3=new HashSet<>();hashSet3.add("成都");hashSet3.add("上海");hashSet3.add("杭州");HashSet<String> hashSet4=new HashSet<>();hashSet4.add("上海");hashSet4.add("天津");HashSet<String> hashSet5=new HashSet<>();hashSet5.add("杭州");hashSet5.add("大連");//加入到Mapbroadcasts.put("K1",hashSet1);broadcasts.put("K2",hashSet2);broadcasts.put("K3",hashSet3);broadcasts.put("K4",hashSet4);broadcasts.put("K5",hashSet5);//存放所有地區HashSet<String> allAreas = new HashSet<>();allAreas.add("北京");allAreas.add("上海");allAreas.add("天津");allAreas.add("廣州");allAreas.add("深圳");allAreas.add("成都");allAreas.add("杭州");allAreas.add("大連");//創建ArrayList,存放選擇的電臺集合ArrayList<String> selects=new ArrayList<>();//定義一個臨時的集合,在遍歷的過程中,存放遍歷過程中的電臺覆蓋的地區和當前還沒有覆蓋的地區的交集HashSet<String> tempSet=new HashSet<>();//定義一個maxKey,保存在一次遍歷中,能夠覆蓋最大未覆蓋的的地區對應的電臺key//如果maxKey 不為 null ,則會加入到selectsString maxKey=null;while (allAreas.size()!=0){ //如果allAreas不為0,則表示還沒有覆蓋到所有的地區//每進行一次while,需要將maxKey置空maxKey=null;//遍歷broadcast,取出對應的keyfor (String key:broadcasts.keySet()){//每進行一次for都需要將tempSet中的數據清除tempSet.clear();//當前這個key能夠覆蓋的地區HashSet<String> areas=broadcasts.get(key);tempSet.addAll(areas);//求出tempSet和allAreas 集合的交集,交集會付給tempSet//tempSet.retainAll(allAreas); 把tempSet 和allAreas 共有的部分 取出來,賦給tempSettempSet.retainAll(allAreas);//如果當前這個集合包含的未覆蓋地區的數量,比maxKey指向的集合地區還多//就需要重置maxKey//tempSet.size()>broadcasts.get(key).size() 體現出貪心算法的特點,每次都選擇最優的if (tempSet.size()>0&&(maxKey==null||tempSet.size()>broadcasts.get(key).size())){maxKey=key;}}//maxKey != null,就應該將maxKey加入到 selectsif (maxKey!=null){selects.add(maxKey);//將maxKey指向的廣播電臺覆蓋的地區,從allAreas中去掉allAreas.removeAll(broadcasts.get(maxKey));}}System.out.println("得到的結果是:"+selects);} }6、普利姆算法
最小生成樹
最小生成樹(Minimum Cost Spanning Tree),簡稱MST。
給定一個帶權的無向連通圖,如何選取一棵生成樹,使樹上所有邊上權的總和為最小,這叫最小生成樹
N個頂點,一定有N-1條邊
包含全部頂點
N-1條邊都在圖中
求最小生成樹的算法主要是普里姆算法和克魯斯卡爾算法
簡單介紹
1)普利姆(Prim)算法求最小生成樹,也就是在包含n個頂點的連通圖中,找出只有(n-1)條邊包含所有n個頂點的連通子圖,也就是所謂的極小連通子圖
2)普利姆的算法如下:
(1)設G=(V,E)是連通網,T=(U,D)是最小生成樹,V,U是頂點集合,E,D是邊的集合
(2)若從頂點u開始構造最小生成樹,則從集合V中取出頂點u放入集合U中,標記頂點v的visited[u]=1
(3)若集合U中頂點ui與集合V-U中的頂點vj之間存在邊,則尋找這些邊中權值最小的邊,但不能構成回路,將頂點vj加入集合U中,將邊(ui,vj)加入集合D中,標記visited[vj]=1
(4)重復步驟②,直到U與V相等,即所有頂點都被標記為訪問過,此時D中有n-1條邊
應用場景(修理問題)
1)有勝利鄉有7個村莊(A, B, C, D, E, F, G) ,現在需要修路把7個村莊連通
2)各個村莊的距離用邊線表示(權) ,比如 A – B 距離 5公里
3)問:如何修路保證各個村莊都能連通,并且總的修建公路總里程最短?
思路: 將10條邊,連接即可,但是總的里程數不是最小.
正確的思路,就是盡可能的選擇少的路線,并且每條路線最小,保證總里程數最少.
代碼展示
package demo07;import java.util.Arrays;public class PrimAlgorithm {public static void main(String[] args) {//測試看看圖是否創建成功char[] data = new char[]{'A', 'B', 'C', 'D', 'E', 'F', 'G'};int verxs = data.length;//鄰接矩陣的關系使用二維數組表示,10000這個大數,表示兩個點不連通int[][] weight = new int[][]{{10000, 5, 7, 10000, 10000, 10000, 2},{5, 10000, 10000, 9, 10000, 10000, 3},{7, 10000, 10000, 10000, 8, 10000, 10000},{10000, 9, 10000, 10000, 10000, 4, 10000},{10000, 10000, 8, 10000, 10000, 5, 4},{10000, 10000, 10000, 4, 5, 10000, 6},{2, 3, 10000, 10000, 4, 6, 10000}};//創建一個MGraph對象MGraph graph=new MGraph(verxs);//創建一個MinTree對象MinTree minTree=new MinTree();minTree.createGraph(graph,verxs,data,weight);//輸出minTree.showGraph(graph);//測試普利姆算法minTree.prim(graph,0);} }//創建最小生成樹 -> 村莊路線圖 class MinTree {/*** 創建圖的鄰接矩陣** @param graph 圖對象* @param verxs 圖對應的頂點個數* @param data 圖的各個頂點的值* @param weight 圖的鄰接矩陣*/public void createGraph(MGraph graph, int verxs, char[] data, int[][] weight) {int i, j;for (i = 0; i < verxs; i++) { //頂點graph.data[i] = data[i];for (j = 0; j < verxs; j++) {graph.weight[i][j] = weight[i][j];}}}//顯示圖的方法 就是顯示圖的鄰接矩陣public void showGraph(MGraph graph) {for (int[] link : graph.weight) {System.out.println(Arrays.toString(link));}}/*** 編寫Prim算法,生成最小生成樹* @param graph 圖* @param v 表示從圖的第幾個頂點開始生成 'A'-0 'B'-1...*/public void prim(MGraph graph,int v){//visited[] 標記結點(頂點) 是否被訪問過int[] visited=new int[graph.verxs];//visited[] 默認元素的值都是0,表示沒有訪問過for (int i = 0; i < graph.verxs; i++) {visited[i]=0;}//把當前這個節點標記為已訪問visited[v] = 1;// h1 和 h2 記錄兩個頂點的下標int h1=-1;int h2=-1;int minWeight=10000; //將 minWeight 初始成一個大叔,后面遍歷過程中,會被替換for (int k = 1; k < graph.verxs; k++) { // 因為有 graph.verxs 個頂點,普利姆算法結束后有 graph.verxs-1 條邊//這個是確定每一次生成的子圖,和那個結點的距離最近for (int i = 0; i < graph.verxs; i++) { // i 結點表示被訪問過的結點for (int j = 0; j < graph.verxs; j++) { //j 結點表示沒有被訪問過的結點if (visited[i] ==1 && visited[j]==0&&graph.weight[i][j]<minWeight){//替換minWeight (尋找已經訪問過的結點和未訪問過的結點的權值最小的邊)minWeight=graph.weight[i][j];h1=i;h2=j;}}}//找到一條邊是最小System.out.println("邊<"+graph.data[h1]+","+graph.data[h2]+">權值為:"+minWeight);//將當前這個節點標記為已經訪問visited[h2] = 1;// minWeight 重新設置為最大值 10000minWeight=10000;}}}class MGraph {int verxs; //表示圖的節點個數char[] data; //存放結點數據int[][] weight; //存放邊,就是鄰接矩陣public MGraph(int verxs) {this.verxs = verxs;data = new char[verxs];weight = new int[verxs][verxs];} }7、克魯斯卡爾算法
簡單介紹
1)克魯斯卡爾(Kruskal)算法,是用來求加權連通圖的最小生成樹的算法。
2)基本思想:按照權值從小到大的順序選擇n-1條邊,并保證這n-1條邊不構成回路
3)具體做法:首先構造一個只含n個頂點的森林,然后依權值從小到大從連通網中選擇邊加入到森林中,并使森林中不產生回路,直至森林變成一棵樹為止
思路分析1、最小生成樹
在含有n個頂點的連通圖中選擇n-1條邊,構成一棵極小連通子圖,并使該連通子圖中n-1條邊上權值之和達到最小,則稱其為連通網的最小生成樹。
例如,對于如上圖G4所示的連通網可以有多棵權值總和不相同的生成樹
思路分析2、算法圖解
以上圖G4為例,來對克魯斯卡爾進行演示(假設,用數組R保存最小生成樹結果)。
第1步:將邊<E,F>加入R中。
邊<E,F>的權值最小,因此將它加入到最小生成樹結果R中。
第2步:將邊<C,D>加入R中。
上一步操作之后,邊<C,D>的權值最小,因此將它加入到最小生成樹結果R中。
第3步:將邊<D,E>加入R中。
上一步操作之后,邊<D,E>的權值最小,因此將它加入到最小生成樹結果R中。
第4步:將邊<B,F>加入R中。
上一步操作之后,邊<C,E>的權值最小,但<C,E>會和已有的邊構成回路;因此,跳過邊<C,E>。同理,跳過邊<C,F>。將邊<B,F>加入到最小生成樹結果R中。
第5步:將邊<E,G>加入R中。
上一步操作之后,邊<E,G>的權值最小,因此將它加入到最小生成樹結果R中。
第6步:將邊<A,B>加入R中。
上一步操作之后,邊<F,G>的權值最小,但<F,G>會和已有的邊構成回路;因此,跳過邊<F,G>。同理,跳過邊<B,C>。將邊<A,B>加入到最小生成樹結果R中。
此時,最小生成樹構造完成!它包括的邊依次是:<E,F> <C,D> <D,E> <B,F> <E,G> <A,B>
思路分析3、算法分析
根據前面介紹的克魯斯卡爾算法的基本思想和做法,我們能夠了解到,克魯斯卡爾算法重點需要解決的以下兩個問題:
問題一 對圖的所有邊按照權值大小進行排序。
問題二 將邊添加到最小生成樹中時,怎么樣判斷是否形成了回路。
問題一很好解決,采用排序算法進行排序即可。
問題二,處理方式是:記錄頂點在"最小生成樹"中的終點,頂點的終點是"在最小生成樹中與它連通的最大頂點"。然后每次需要將一條邊添加到最小生存樹時,判斷該邊的兩個頂點的終點是否重合,重合的話則會構成回路。
思路分析4、判斷是否構成回路
在將<E,F> <C,D> <D,E>加入到最小生成樹R中之后,這幾條邊的頂點就都有了終點:
? (01) C的終點是F。
(02) D的終點是F。
(03) E的終點是F。
? (04) F的終點是F。
關于終點的說明:
因此,接下來,雖然<C,E>是權值最小的邊。但是C和E的終點都是F,即它們的終點相同,因此,將<C,E>加入最小生成樹的話,會形成回路。這就是判斷回路的方式。也就是說,我們加入的邊的兩個頂點不能都指向同一個終點,否則將構成回路。【后面有代碼說明】
代碼展示
package demo08;import java.util.Arrays;//克魯斯卡爾算法 解決 公交問題 public class KruskalCase {private int edgeNum; //記錄邊的個數private char[] vertexs; //頂點數組private int[][] matrix; //鄰接矩陣//使用 INF 表示兩個頂點不能連通private static final int INF = Integer.MAX_VALUE;public static void main(String[] args) {char[] vertexs = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};int[][] matrix = {/*A B C D E F G *//* A */ {0, 12, INF, INF, INF, 16, 14},/* B */ {12, 0, 10, INF, INF, 7, INF},/* C */ {INF, 10, 0, 3, 5, 6, INF},/* D */ {INF, INF, 3, 0, 4, INF, INF},/* E */ {INF, INF, 5, 4, 0, 2, 8},/* F */ {16, 7, 6, INF, 2, 0, 9},/* G */ {14, INF, INF, INF, 8, 9, 0}};//創建KruskalCase 對象實例KruskalCase kruskalCase = new KruskalCase(vertexs, matrix);kruskalCase.print();EDate[] edges = kruskalCase.getEdges();//未排序System.out.println(Arrays.toString(edges));//已排序kruskalCase.sortEdge(edges);System.out.println(Arrays.toString(edges));kruskalCase.kruskal();}//public void kruskal() {int index = 0; //表示最后結果數組的索引int[] ends = new int[edgeNum]; //用于保存 “已有最小生成樹” 中的每個頂點在最小生成樹中的終點//創建結果數組 保存最后的最小生成樹EDate[] rets = new EDate[edgeNum];//先獲取圖中所有的邊的集合EDate[] edges = getEdges();System.out.println("圖的邊的集合" + Arrays.toString(edges) + "共" + edges.length + "條邊");//按照邊的權值大小進行排序(從小到大)sortEdge(edges);//遍歷 edges 數組,將邊添加到最小生成樹中時,判斷準備加入的邊是否構成回路,如果沒有,就加入 rets,否則不能加入for (int i = 0; i < edgeNum; i++) {//獲取到第 i 條邊的第一個頂點(起點)int p1 = getPosition(edges[i].start); //p1//獲取第 i 條邊的第2個頂點int p2 = getPosition(edges[i].end);//獲取p1這個頂點在已有最小生成樹中的終點int m = getEnd(ends, p1);//取p1這個頂點在已有最小生成樹中的終點int n = getEnd(ends, p2);//判斷是否構成回路if (m != n) {//說明沒有構成回路ends[m] = n; // 設置m在 “已有最小生成樹” 中的終點 <E,F> [0,0,0,0,0,0,0,0,0,0,0,0]rets[index++] = edges[i];//有一條邊 加入到}}//統計并打印 “最小生成樹” ,輸出 retsSystem.out.println("最小生成樹為");for (int i = 0; i < index; i++) {System.out.println(rets[i]);}}//構造器public KruskalCase(char[] vertexs, int[][] matrix) {//初始化頂點數和邊的個數int vlen = vertexs.length;//初始化頂點,復制拷貝的方式this.vertexs = new char[vlen];for (int i = 0; i < vertexs.length; i++) {this.vertexs[i] = vertexs[i];}//初始化邊,使用的是復制拷貝的方式this.matrix = new int[vlen][vlen];for (int i = 0; i < vlen; i++) {for (int j = 0; j < vlen; j++) {this.matrix[i][j] = matrix[i][j];}}//統計邊的條數for (int i = 0; i < vlen; i++) {for (int j = i + 1; j < vlen; j++) {if (this.matrix[i][j] != INF) {edgeNum++;}}}}//打印鄰接矩陣public void print() {System.out.println("鄰接矩陣為:");for (int i = 0; i < vertexs.length; i++) {for (int j = 0; j < vertexs.length; j++) {System.out.printf("%12d\t", matrix[i][j]);}//換行處理System.out.println();}}/*** 對邊的權值進行排序處理冒泡排序** @param edges 邊的集合*/private void sortEdge(EDate[] edges) {for (int i = 0; i < edges.length - 1; i++) {for (int j = 0; j < edges.length - 1 - i; j++) {if (edges[j].weight > edges[j + 1].weight) {//交換EDate tmp = edges[j];edges[j] = edges[j + 1];edges[j + 1] = tmp;}}}}/*** @param ch 頂點的值,比如'A' 'B'* @return 返回 ch 頂點對應的下標,如果找不到,返回 -1*/private int getPosition(char ch) {for (int i = 0; i < vertexs.length; i++) {if (vertexs[i] == ch) { //找到return i;}}//找不到 返回 -1return -1;}/*** 功能:獲取圖中邊,放到EDate[] 數組中,后面我們需要遍歷該數組* 是通過matrix 鄰接矩陣來獲取* EDate 形式[['A','B',12],['B','F',7]...]** @return*/private EDate[] getEdges() {int index = 0;EDate[] edges = new EDate[edgeNum];for (int i = 0; i < vertexs.length; i++) {for (int j = i + 1; j < vertexs.length; j++) {if (matrix[i][j] != INF) {edges[index++] = new EDate(vertexs[i], vertexs[j], matrix[i][j]);}}}return edges;}/*** 獲取下標為 i 的頂點的終點,用于后面判斷兩個頂點的終點是否相同** @param ends 數組就是記錄了各個頂點對應的終點是哪個, ends 數組是在遍歷過程中逐步形成的* @param i 表示傳入的頂點對應的下標* @return 返回下標為 i的這個頂點對應的終點的下標*/private int getEnd(int[] ends, int i) {while (ends[i] != 0) {i = ends[i];}return i;}}//創建一個類EDate,它的對象實例就是一條邊 class EDate {char start; //邊的一個點char end; //邊的另一個店int weight; //邊的權值//構造器public EDate(char start, char end, int weight) {this.start = start;this.end = end;this.weight = weight;}//重寫toString方法,便于輸出邊@Overridepublic String toString() {return "EDate{<" + start + "," + end + "> = " + weight + '}';} }8、迪杰斯特拉算法
簡單介紹
迪杰斯特拉(Dijkstra)算法是典型最短路徑算法,用于計算一個結點到其他結點的最短路徑。 它的主要特點是以起始點為中心向外層層擴展(廣度優先搜索思想),直到擴展到終點為止
思路分析
設置出發頂點為v,頂點集合V{v1,v2,vi…},v到V中各頂點的距離構成距離集合Dis,Dis{d1,d2,di…},Dis集合記錄著v到圖中各頂點的距離(到自身可以看作0,v到vi距離對應為di)
1)從Dis中選擇值最小的di并移出Dis集合,同時移出V集合中對應的頂點vi,此時的v到vi即為最短路徑
2)更新Dis集合,更新規則為:比較v到V集合中頂點的距離值,與v通過vi到V集合中頂點的距離值,保留值較小的一個(同時也應該更新頂點的前驅節點為vi,表明是通過vi到達的)
3)重復執行兩步驟,直到最短路徑頂點為目標頂點即可結束
應用場景-最短路徑
1)戰爭時期,勝利鄉有7個村莊(A, B, C, D, E, F, G) ,現在有六個郵差,從G點出發,需要分別把郵件分別送到 A, B, C , D, E, F 六個村莊
2)各個村莊的距離用邊線表示(權) ,比如 A – B 距離 5公里
3)問:如何計算出G村莊到 其它各個村莊的最短距離?
4)如果從其它點出發到各個點的最短距離又是多少?
代碼展示
package demo09;import java.util.Arrays;public class DijkstraAlforithm {public static void main(String[] args) {char[] vertex = new char[]{'A', 'B', 'C', 'D', 'E', 'F', 'G'};//鄰接矩陣int[][] matrix = new int[vertex.length][vertex.length];final int N = 65535;//表示不可連接matrix[0] = new int[]{N, 5, 7, N, N, N, 2};matrix[1] = new int[]{5, N, N, 9, N, N, 3};matrix[2] = new int[]{7, N, N, N, 8, N, N};matrix[3] = new int[]{N, 9, N, N, N, 4, N};matrix[4] = new int[]{N, N, 8, N, N, 5, 4};matrix[5] = new int[]{N, N, N, 4, 5, N, 6};matrix[6] = new int[]{2, 3, N, N, 4, 6, N};//創建Graph對象Graph graph = new Graph(vertex, matrix);//測試,看看圖的鄰接矩陣是否OKgraph.show();//測試一把迪杰斯特拉算法graph.dijkstra(6);graph.showDijkstra();} }//創建圖 class Graph {private char[] vertex; //頂點數組private int[][] matrix; //鄰接矩陣private VisitedVertex vv; //已經訪問的頂點的集合//構造器public Graph(char[] vertex, int[][] matrix) {this.vertex = vertex;this.matrix = matrix;}//顯示圖public void show() {for (int[] link : matrix) {System.out.println(Arrays.toString(link));}}//迪杰斯特拉算法實現public void dijkstra(int index) {vv = new VisitedVertex(vertex.length, index);update(index); //更新index頂點到周圍頂點的距離和前驅頂點for (int j = 1; j < vertex.length; j++) {index=vv.updateArr();//選擇并返回新的訪問頂點update(index); //更新index頂點到周圍頂點的距離和前驅頂點}}//更新index下標頂點到周圍頂點的距離和中歐為頂點的前驅頂點private void update(int index) {int len = 0;//根據遍歷我們的鄰接矩陣 matrix[index]for (int j = 0; j < matrix[index].length; j++) {// len 含義是:出發頂點到index頂點的距離 + 從 index 到 j 頂點的距離的和len = vv.getDis(index) + matrix[index][j];//如果 j 頂點沒有被訪問過,并且len 小于出發頂點到 j 頂點 的距離,就需要更新if (!vv.in(j) && len < vv.getDis(j)) {vv.updatePre(j, index); //更新 j 頂點的前驅為 index 頂點vv.updateDis(j, len); // 更新出發頂點到 j 頂點的距離}}}public void showDijkstra(){vv.show();}}//已訪問頂點的集合 class VisitedVertex {//記錄各個頂點是否訪問,1表示訪問過,0未訪問,會動態更新public int[] already_arr;//每個下標對應的值為前一個頂點下標,會動態更新public int[] pre_visited;//記錄出發頂點到其他所有頂點的距離,比如 G 為出發頂點,就會記錄G到其他頂點的距離,會動態更新,求出的最短距離就會記錄到dispublic int[] dis;/*** 構造器** @param length 表示頂點的個數* @param index 表示出發頂點對應的下標 比如G頂點,下標就是6*/public VisitedVertex(int length, int index) {this.already_arr = new int[length];this.pre_visited = new int[length];this.dis = new int[length];//初始化 dis 數組Arrays.fill(dis, 65535);this.already_arr[index] = 1; //設置出發訂單被訪問為1this.dis[index] = 0;//設置出發頂點的訪問距離為0}/*** 判斷index頂點是否被訪問過** @param index* @return 如果被訪問過,就返回true,否則返回false*/public boolean in(int index) {return already_arr[index] == 1;}/*** 更新出發頂點到index頂點的距離** @param index* @param len*/public void updateDis(int index, int len) {dis[index] = len;}/*** 更新pre這個頂點的前驅頂點為index頂點** @param pre* @param index*/public void updatePre(int pre, int index) {pre_visited[pre] = index;}/*** 返回出發頂點到index頂點的距離** @param index*/public int getDis(int index) {return dis[index];}//繼續選擇并返回新的訪問頂點,比如G點完后,就是A點作為新的訪問頂點(注意不是出發頂點)public int updateArr() {int min = 65535, index = 0;for (int i = 0; i < already_arr.length; i++) {if (already_arr[i] == 0 && dis[i] < min) {min = dis[i];index = i;}}//更新index,頂點被訪問過already_arr[index]=1;return index;}//顯示最后的結果//即將三個數組的情況輸出public void show(){System.out.println();//輸出already_arrfor (int i : already_arr) {System.out.print(i+" ");}System.out.println();//輸出pre_visitedfor (int i : pre_visited){System.out.print(i+" ");}System.out.println();//輸出disfor (int i : dis){System.out.print(i+" ");}}}9、弗洛伊德算法
簡單介紹
1、和Dijkstra算法一樣,弗洛伊德(Floyd)算法也是一種用于尋找給定的加權圖中頂點間最短路徑的算法。該算法名稱以創始人之一、1978年圖靈獎獲得者、斯坦福大學計算機科學系教授羅伯特·弗洛伊德命名
2、弗洛伊德算法(Floyd)計算圖中各個頂點之間的最短路徑
3、迪杰斯特拉算法用于計算圖中某一個頂點到其他頂點的最短路徑。
4、弗洛伊德算法 VS 迪杰斯特拉算法:迪杰斯特拉算法通過選定的被訪問頂點,求出從出發訪問頂點到其他頂點的最短路徑;弗洛伊德算法中每一個頂點都是出發訪問點,所以需要將每一個頂點看做被訪問頂點,求出從每一個頂點到其他頂點的最短路徑。
思路分析
1)設置頂點vi到頂點vk的最短路徑已知為Lik,頂點vk到vj的最短路徑已知為Lkj,頂點vi到vj的路徑為Lij,則vi到vj的最短路徑為:min((Lik+Lkj),Lij),vk的取值為圖中所有頂點,則可獲得vi到vj的最短路徑
2)至于vi到vk的最短路徑Lik或者vk到vj的最短路徑Lkj,是以同樣的方式獲得
3)弗洛伊德(Floyd)算法圖解分析-舉例說明
應用場景
1)戰爭時期,勝利鄉有7個村莊(A, B, C, D, E, F, G) ,現在有六個郵差,從G點出發,需要分別把郵件分別送到 A, B, C , D, E, F 六個村莊
2)各個村莊的距離用邊線表示(權) ,比如 A – B 距離 5公里
3)問:如何計算出各村莊到 其它各村莊的最短距離?
代碼展示
package demo10;import java.util.Arrays;//弗洛伊德算法 public class FloydAlgorithm {public static void main(String[] args) {//測試看看圖是否創建成功char[] vertex = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};//創建鄰接矩陣int[][] matrix = new int[vertex.length][vertex.length];final int N = 65535;matrix[0] = new int[]{0, 5, 7, N, N, N, 2};matrix[1] = new int[]{5, 0, N, 9, N, N, 3};matrix[2] = new int[]{7, N, 0, N, 8, N, N};matrix[3] = new int[]{N, 9, N, 0, N, 4, N};matrix[4] = new int[]{N, N, 8, N, 0, 5, 4};matrix[5] = new int[]{N, N, N, 4, 5, 0, 6};matrix[6] = new int[]{2, 3, N, N, 4, 6, 0};//創建一個圖對象Graph graph = new Graph(vertex.length, matrix, vertex);//調用 floyd()graph.floyd();graph.show();} }//創建圖 class Graph {private char[] vertex; //存放頂點數組private int[][] dis; //保存從各個頂點出發到其他頂點的距離,最后結果也保存在該數組中private int[][] pre; //保存到達目標頂點的前驅頂點/*** 構造器** @param length 大小* @param matrix 鄰接矩陣* @param vertex 頂點數組*/public Graph(int length, int[][] matrix, char[] vertex) {this.vertex = vertex;this.dis = matrix;this.pre = new int[length][length];//對pre數組初始化,存放的是前驅頂點的下標for (int i = 0; i < length; i++) {Arrays.fill(pre[i], i);}}//顯示方法,顯示dis數組和pre數組public void show() {//為了便于查看char[] vertex = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};for (int k = 0; k < dis.length; k++) {//先將pre數組輸出的一行數據for (int i = 0; i < dis.length; i++) {System.out.print(vertex[pre[k][i]] + " ");}System.out.println();//輸出dis 的一行數據for (int i = 0; i < dis.length; i++) {System.out.print("(" + vertex[k] + "到" + vertex[i] + "的最短路徑是" + dis[k][i] + ") ");}System.out.println();System.out.println();}}//弗洛伊德算法public void floyd() {int len = 0; //變量保存距離//對中間頂點遍歷,k就是中間頂點下標for (int k = 0; k < dis.length; k++) {//從 i 頂點開始出發 ['A', 'B', 'C', 'D', 'E', 'F', 'G']for (int i = 0; i < dis.length; i++) {//到達終點 j ['A', 'B', 'C', 'D', 'E', 'F', 'G']for (int j = 0; j < dis.length; j++) {len = dis[i][k] + dis[k][j]; // => 求出從 i 頂點出發,經過k中間頂點,到達j頂點距離if (len < dis[i][j]) { //如果len 小于 dis[i][j]dis[i][j] = len; // 更新距離pre[i][j] = pre[k][j]; //更新前驅頂點}}}}}}10、馬踏棋盤算法
游戲展示
馬踏棋盤算法介紹和游戲演示
1)馬踏棋盤算法也被稱為騎士周游問題
2)將馬隨機放在國際象棋的8×8棋盤Board[0~7][0~7]的某個方格中,馬按走棋規則(馬走日字)進行移動。要求每個方格只進入一次,走遍棋盤上全部64個方格
思路分析
1)馬踏棋盤問題(騎士周游問題)實際上是圖的深度優先搜索(DFS)的應用。
2)如果使用回溯(就是深度優先搜索)來解決,假如馬兒踏了53個點,如圖:走到了第53個,坐標(1,0),發現已經走到盡頭,沒辦法,那就只能回退了,查看其他的路徑,就在棋盤上不停的回溯…… ,思路分析+代碼實現
3)分析第一種方式的問題,并使用貪心算法(greedyalgorithm)進行優化。解決馬踏棋盤問題.
使用前面的游戲來驗證算法是否正確
解決步驟
注意:馬兒不同的走法(策略),會得到不同的結果,效率也會有影響(優化)
//創建一個Point Point p1 = new Point(); if((p1.x = curPoint.x - 2) >= 0 && (p1.y = curPoint.y -1) >= 0) {ps.add(new Point(p1)); }使用貪心算法對原來的算法優化
1. 我們獲取當前位置,可以走的下一個位置的集合 //獲取當前位置可以走的下一個位置的集合 ArrayList<Point> ps = next(new Point(column, row)); 2. 我們需要對 ps 中所有的Point 的下一步的所有集合的數目,進行非遞減排序,就ok , 9, 7, 6, 5, 3, 2, 1 //遞減排序1, 2, 3, 4, 5, 6, 10, //遞增排序1, 2, 2, 2, 3, 3, 4, 5, 6 // 非遞減 遞增,但有重復數9, 7, 6, 6, 6, 5, 5, 3, 2, 1 //非遞增 遞減,但有重復數代碼展示
package demo11;import java.awt.*; import java.util.ArrayList; import java.util.Comparator;public class HorseChessborad {private static int X; //表示棋盤的列數private static int Y; //表示棋盤的行數//創建一個數組,標記棋盤的各個位置是否被訪問過private static boolean[] visited;//使用一個屬性標記是否棋盤的所有位置都被標記private static boolean finished; //如果為true,表示成功public static void main(String[] args) {System.out.println("騎士周游算法,開始執行~~");//測試騎士周游算法是否正確X=8;Y=8;int row=1; //馬兒初始位置的行,從1開始編號int column=1; //馬兒初始位置的列,從1開始編號//創建棋盤int[][] chessboard=new int[X][Y];visited=new boolean[X*Y];// 初始值都是false//測試耗時long start = System.currentTimeMillis();traversalChessboard(chessboard,row-1,column-1,1);long end = System.currentTimeMillis();System.out.println("共耗時:"+(end-start)+"毫秒");//輸出棋盤的最后情況for (int[] rows:chessboard){for (int step:rows){System.out.print(step+"\t");}System.out.println();}}/*** 完成騎士周游問題的算法** @param chessboard 棋盤* @param row 馬兒當前的位置的行 從0開始* @param column 馬兒當前的位置的列 從0開始* @param step 是第幾步,初始位置就是第一步*/public static void traversalChessboard(int[][] chessboard, int row, int column, int step) {chessboard[row][column] = step;//標記該位置已訪問visited[row * X + column] = true;//獲取當前位置可以走的下一個位置的集合ArrayList<Point> points = next(new Point(column, row));//對points進行排序,排序的規則就是對points的所有的Point對象的下一步的位置的數目,進行非遞減排序//優化方法sort(points);//遍歷pointswhile (!points.isEmpty()) {Point p = points.remove(0);//取出下一個可以走的位置//判斷該點是否已經訪問過if (!visited[p.y * X + p.x]) {//說明還沒有訪問過traversalChessboard(chessboard, p.y, p.x, step + 1);}}//判斷馬兒是否完成任務,使用 step 和應該走的步數比較//如果沒有達到數量,則表示沒有完成任務,將整個棋盤置 0//說明//step < X * Y 成立的情況有兩種//1. 棋盤到目前位置,仍然沒有走完//2. 棋盤處于一個回溯過程if (step < X * Y && !finished) {chessboard[row][column] = 0;visited[row * X + column] = false;}else {finished=true;}}/*** 功能:根據當前位置(Point),計算馬兒還能走哪些位置(Point),并放入到一個集合中(ArrayList),最多有8個位置** @param curPoint* @return*/public static ArrayList<Point> next(Point curPoint) {//創建一個ArrayListArrayList<Point> points = new ArrayList<>();//創建一個PointPoint p1 = new Point();//判斷馬兒能走5的位置(根據上文展示的圖判斷)if ((p1.x = curPoint.x - 2) >= 0 && (p1.y = curPoint.y - 1) >= 0) {points.add(new Point(p1));}//判斷馬兒能走6的位置(根據上文展示的圖判斷)if ((p1.x = curPoint.x - 1) >= 0 && (p1.y = curPoint.y - 2) >= 0) {points.add(new Point(p1));}//判斷馬兒能走7的位置(根據上文展示的圖判斷)if ((p1.x = curPoint.x + 1) < X && (p1.y = curPoint.y - 2) >= 0) {points.add(new Point(p1));}//判斷馬兒能走0的位置(根據上文展示的圖判斷)if ((p1.x = curPoint.x + 2) < X && (p1.y = curPoint.y - 1) >= 0) {points.add(new Point(p1));}//判斷馬兒能走1的位置(根據上文展示的圖判斷)if ((p1.x = curPoint.x + 2) < X && (p1.y = curPoint.y + 1) < Y) {points.add(new Point(p1));}//判斷馬兒能走2的位置(根據上文展示的圖判斷)if ((p1.x = curPoint.x + 1) < X && (p1.y = curPoint.y + 2) < Y) {points.add(new Point(p1));}//判斷馬兒能走3的位置(根據上文展示的圖判斷)if ((p1.x = curPoint.x - 1) >= 0 && (p1.y = curPoint.y + 2) < Y) {points.add(new Point(p1));}//判斷馬兒能走4的位置(根據上文展示的圖判斷)if ((p1.x = curPoint.x - 2) >= 0 && (p1.y = curPoint.y + 1) < Y) {points.add(new Point(p1));}return points;}//優化//根據當前這一步的所有的下一步的選擇位置,進行非遞減排序,減少回溯的可能public static void sort(ArrayList<Point> points){points.sort(new Comparator<Point>() {@Overridepublic int compare(Point o1, Point o2) {//獲取到o1點的下一步的所有的位置個數int count1 = next(o1).size();//獲取到o2點的下一步的所有的位置個數int count2 = next(o2).size();if (count1<count2){return -1;}else if (count1==count2){return 0;}else {return 1;}}});}}總結
以上是生活随笔為你收集整理的14.程序员常用10种算法的全部內容,希望文章能夠幫你解決所遇到的問題。

- 上一篇: python 批量打开网页并截图_如何实
- 下一篇: 双线性变换(Tustin transfo