YOLO_ Real-Time Object Detection 实时目标检测
YOLO: Real-Time Object Detection 實(shí)時目標(biāo)檢測
You only look once(YOLO)是一種先進(jìn)的實(shí)時目標(biāo)檢測系統(tǒng)。在Pascal Titan X上,它以每秒30幀的速度處理圖像,在COCO test-dev上有57.9%的mAP。
與其他探測器的比較
YOLOv3是非常快速和準(zhǔn)確的。在0.5 IOU下測得的mAP中,YOLOv3與Focal Loss相當(dāng),但速度快了4倍左右。此外,您可以輕松地在速度和精度之間進(jìn)行折衷,只需更改模型的大小,而無需重新培訓(xùn)!
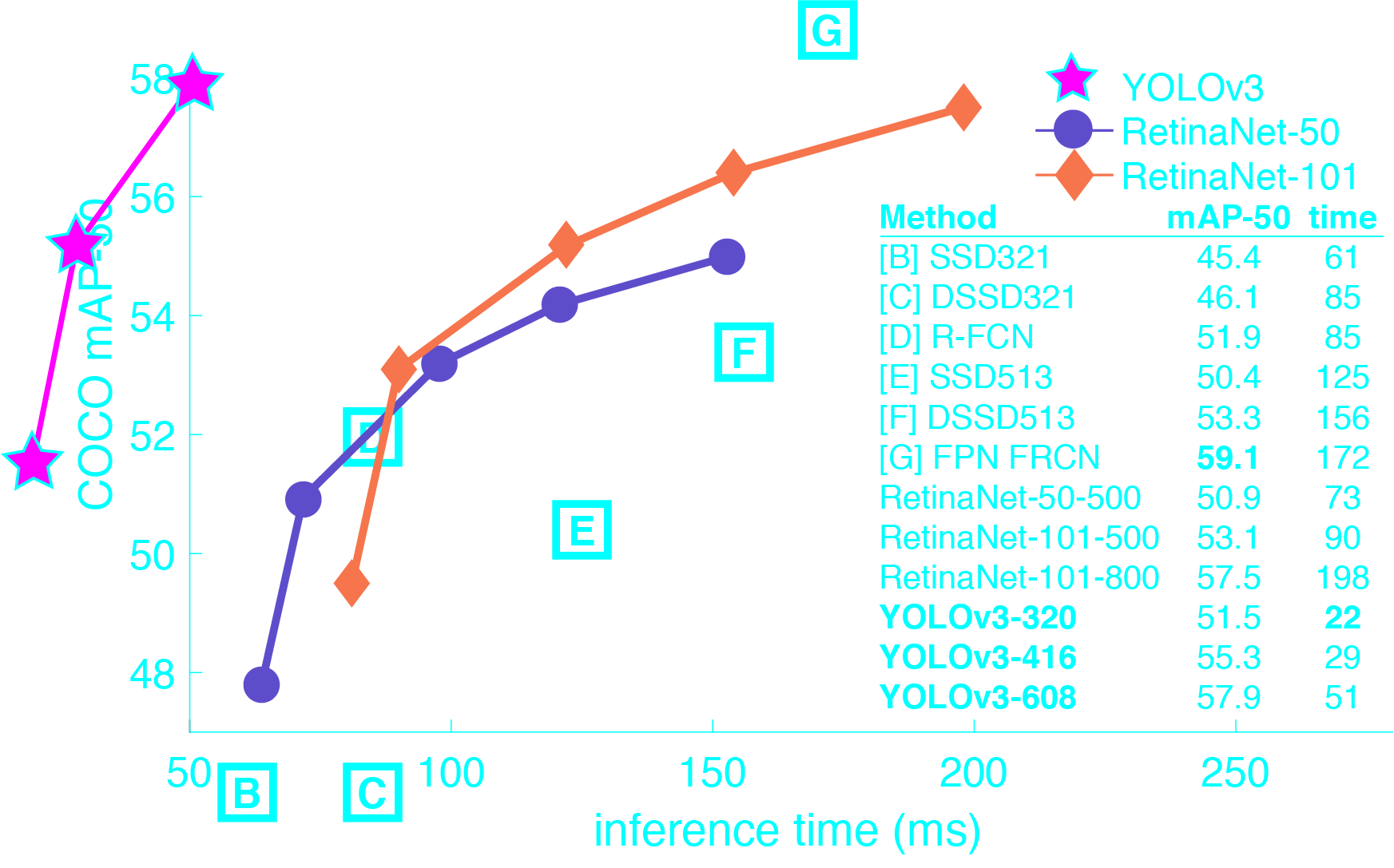
COCO數(shù)據(jù)集上的性能
| SSD300 | COCO trainval | test-dev | 41.2 | - | 46 | link | |
| SSD500 | COCO trainval | test-dev | 46.5 | - | 19 | link | |
| YOLOv2 608x608 | COCO trainval | test-dev | 48.1 | 62.94 Bn | 40 | cfg | weights |
| Tiny YOLO | COCO trainval | test-dev | 23.7 | 5.41 Bn | 244 | cfg | weights |
| — | |||||||
| SSD321 | COCO trainval | test-dev | 45.4 | - | 16 | link | |
| DSSD321 | COCO trainval | test-dev | 46.1 | - | 12 | link | |
| R-FCN | COCO trainval | test-dev | 51.9 | - | 12 | link | |
| SSD513 | COCO trainval | test-dev | 50.4 | - | 8 | link | |
| DSSD513 | COCO trainval | test-dev | 53.3 | - | 6 | link | |
| FPN FRCN | COCO trainval | test-dev | 59.1 | - | 6 | link | |
| Retinanet-50-500 | COCO trainval | test-dev | 50.9 | - | 14 | link | |
| Retinanet-101-500 | COCO trainval | test-dev | 53.1 | - | 11 | link | |
| Retinanet-101-800 | COCO trainval | test-dev | 57.5 | - | 5 | link | |
| YOLOv3-320 | COCO trainval | test-dev | 51.5 | 38.97 Bn | 45 | cfg | weights |
| YOLOv3-416 | COCO trainval | test-dev | 55.3 | 65.86 Bn | 35 | cfg | weights |
| YOLOv3-608 | COCO trainval | test-dev | 57.9 | 140.69 Bn | 20 | cfg | weights |
| YOLOv3-tiny | COCO trainval | test-dev | 33.1 | 5.56 Bn | 220 | cfg | weights |
| YOLOv3-spp | COCO trainval | test-dev | 60.6 | 141.45 Bn | 20 | cfg | weights |
工作原理
先前的檢測系統(tǒng)重新利用分類器或定位器來執(zhí)行檢測。它們將模型應(yīng)用于多個位置和比例的圖像。高得分區(qū)域的圖像被認(rèn)為是檢測。
我們使用完全不同的方法。我們將一個神經(jīng)網(wǎng)絡(luò)應(yīng)用于整個圖像。該網(wǎng)絡(luò)將圖像分為多個區(qū)域,并預(yù)測每個區(qū)域的邊界框和概率。這些邊界框由預(yù)測概率加權(quán)。
與基于分類器的系統(tǒng)相比,我們的模型有幾個優(yōu)點(diǎn)。它在測試時查看整個圖像,因此它的預(yù)測是由圖像中的全局上下文通知的。它還可以用一個網(wǎng)絡(luò)評估來進(jìn)行預(yù)測,不像R-CNN那樣的系統(tǒng),一張圖像需要數(shù)千個網(wǎng)絡(luò)評估。這使得它非常快,R-CNN快1000倍以上,比Fast R-CNN快100倍以上。。有關(guān)完整系統(tǒng)的詳細(xì)信息,請參閱我們的paper。
版本3有什么新功能?
YOLOv3使用了一些技巧來改進(jìn)訓(xùn)練和提高性能,包括:多尺度預(yù)測、更好的主干分類器等等。全部細(xì)節(jié)在我們的paper上!
使用預(yù)先訓(xùn)練的模型進(jìn)行檢測
這篇文章將指導(dǎo)你通過使用一個預(yù)先訓(xùn)練好的模型用YOLO系統(tǒng)檢測物體。如果您還沒有安裝Darknet,應(yīng)該先安裝。或者不去讀剛才運(yùn)行的所有內(nèi)容:
git clone https://github.com/pjreddie/darknet cd darknet makeEasy!
cfg/子目錄中已經(jīng)有YOLO的配置文件。你必須在這里下載預(yù)先訓(xùn)練的權(quán)重文件(237 MB)。或者運(yùn)行以下命令:
wget https://pjreddie.com/media/files/yolov3.weights然后啟動探測器!
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg您將看到如下輸出:
layer filters size input output0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs.......105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs106 detection truth_thresh: Using default '1.000000' Loading weights from yolov3.weights...Done! data/dog.jpg: Predicted in 0.029329 seconds. dog: 99% truck: 93% bicycle: 99%Darknet 打印出它檢測到的物體,它的置信度,以及找到它們所花的時間。我們沒有用OpenCV編譯Darknet,所以它不能直接顯示檢測結(jié)果。相反,它將它們保存在predictions.png. 您可以打開它來查看檢測到的對象。因?yàn)槲覀冊贑PU上使用Darknet,所以每個圖像大約需要6-12秒。如果我們使用GPU版本,速度會快得多。
我已經(jīng)提供了一些例子圖片,以防你需要靈感。試用data/eagle.jpg, data/dog.jpg, data/person.jpg, 或 data/horses.jpg!
detect命令是更通用的命令版本的簡寫。它相當(dāng)于命令:
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg如果您只想在一個圖像上運(yùn)行檢測,則不需要知道這一點(diǎn),但如果您想在網(wǎng)絡(luò)攝像頭上運(yùn)行(稍后將看到)等其他操作,則知道這一點(diǎn)非常有用。
多個圖像
不必在命令行中提供圖像,您可以將其保留為空以嘗試一行中的多個圖像。相反,當(dāng)配置和權(quán)重加載完成時,您將看到一個提示:
./darknet detect cfg/yolov3.cfg yolov3.weights layer filters size input output0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs.......104 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs106 detection Loading weights from yolov3.weights...Done! Enter Image Path:輸入圖像路徑,如data/horses.jpg讓它為那個圖像預(yù)測盒子。
一旦完成,它會提示您更多的路徑來嘗試不同的圖像。完成后,使用Ctrl-C退出程序。
更改檢測閾值
默認(rèn)情況下,YOLO只顯示置信度為.25或更高的對象。您可以通過將-thresh標(biāo)志傳遞給yolo命令來改變這一點(diǎn)。例如,要顯示所有檢測,可以將閾值設(shè)置為0:
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg -thresh 0所以這顯然不是非常有用,但是你可以將它設(shè)置為不同的值來控制模型的閾值。
Tiny YOLOv3
我們有一個非常小的模型,也適用于受限環(huán)境,yolov3tiny。要使用此模型,請首先下載權(quán)重:
wget https://pjreddie.com/media/files/yolov3-tiny.weights然后用微小的配置文件和權(quán)重運(yùn)行探測器:
./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg網(wǎng)絡(luò)攝像頭上的實(shí)時檢測
如果看不到結(jié)果,那么在測試數(shù)據(jù)上運(yùn)行YOLO就不是很有趣了。與其在一堆圖像上運(yùn)行它,不如在網(wǎng)絡(luò)攝像頭的輸入上運(yùn)行它!
要運(yùn)行這個演示,你需要用CUDA和OpenCV編譯Darknet。然后運(yùn)行命令:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weightsYOLO將顯示當(dāng)前FPS和預(yù)測類,以及在上面繪制邊界框的圖像。
你需要一個網(wǎng)絡(luò)攝像頭連接到OpenCV可以連接到的計算機(jī)上,否則它將無法工作。如果您連接了多個網(wǎng)絡(luò)攝像頭,并且想要選擇使用哪一個,那么可以傳遞-c標(biāo)志來選擇(OpenCV默認(rèn)使用網(wǎng)絡(luò)攝像頭0)。
如果OpenCV可以讀取視頻,也可以在視頻文件上運(yùn)行:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights <video file>這就是我們制作上述YouTube視頻的方式。
對YOLO進(jìn)行VOC培訓(xùn)
如果您想使用不同的訓(xùn)練模式、超參數(shù)或數(shù)據(jù)集,可以從頭開始訓(xùn)練YOLO。下面是如何讓它在Pascal VOC數(shù)據(jù)集上工作。
獲取Pascal VOC數(shù)據(jù)
為了訓(xùn)練YOLO,你需要2007年到2012年的所有VOC數(shù)據(jù)。你可以在這里找到這些數(shù)據(jù)的鏈接。要獲取所有數(shù)據(jù),請創(chuàng)建一個目錄來存儲所有數(shù)據(jù),然后從該目錄運(yùn)行:
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar tar xf VOCtrainval_11-May-2012.tar tar xf VOCtrainval_06-Nov-2007.tar tar xf VOCtest_06-Nov-2007.tar現(xiàn)在將有一個VOCdevkit/子目錄,其中包含所有VOC訓(xùn)練數(shù)據(jù)。
生成VOC標(biāo)簽
現(xiàn)在我們需要生成Darknet使用的標(biāo)簽文件。Darknet希望每個圖像都有一個.txt文件,圖像中的每個地面真相對象都有一行,如下所示:
<object-class> <x> <y> <width> <height>其中x、y、width和height相對于圖像的寬度和高度。為了生成這些文件,我們將運(yùn)行voc_label.py在Darknet的scripts/目錄中編寫腳本。我們再下載一次吧,因?yàn)槲覀兒軕小?/p> wget https://pjreddie.com/media/files/voc_label.py python voc_label.py
幾分鐘后,這個腳本將生成所有必需的文件。它通常在VOCdevkit/VOC2007/labels/和VOCdevkit/VOC2012/labels/中生成大量標(biāo)簽文件。在您的目錄中,您應(yīng)該看到:
ls 2007_test.txt VOCdevkit 2007_train.txt voc_label.py 2007_val.txt VOCtest_06-Nov-2007.tar 2012_train.txt VOCtrainval_06-Nov-2007.tar 2012_val.txt VOCtrainval_11-May-2012.tar像2007這樣的文本文件_列車.txt列出當(dāng)年的圖像文件和圖像集。Darknet需要一個文本文件,其中包含所有要訓(xùn)練的圖像。在這個例子中,讓我們訓(xùn)練除了2007測試集之外的所有東西,以便我們可以測試我們的模型。運(yùn)行:
cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt現(xiàn)在我們把2007年的trainval和2012年的trainval都列在一個大名單里。這就是我們要做的數(shù)據(jù)設(shè)置!
修改Pascal數(shù)據(jù)的Cfg
現(xiàn)在去你的Darknet文件夾。我們得換cfg/voc.data指向數(shù)據(jù)的配置文件:
1 classes= 202 train = <path-to-voc>/train.txt3 valid = <path-to-voc>2007_test.txt4 names = data/voc.names5 backup = backup應(yīng)該將替換為存放voc數(shù)據(jù)的目錄。
下載預(yù)訓(xùn)練卷積權(quán)重
對于訓(xùn)練,我們使用在Imagenet上預(yù)先訓(xùn)練的卷積權(quán)重。我們使用來自 darknet53 模型的權(quán)重。你可以在這里下載卷積層的權(quán)重(76MB)。
wget https://pjreddie.com/media/files/darknet53.conv.74訓(xùn)練模型
現(xiàn)在我們可以訓(xùn)練了!運(yùn)行命令:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74在COCO上訓(xùn)練YOLO
如果您想使用不同的訓(xùn)練模式、超參數(shù)或數(shù)據(jù)集,可以從頭開始訓(xùn)練YOLO。下面是如何讓它在COCO數(shù)據(jù)集上工作。
獲取COCO數(shù)據(jù)
為了訓(xùn)練YOLO,你需要所有的COCO數(shù)據(jù)和標(biāo)簽。腳本scripts/get_coco_dataset.sh我會幫你的。找出要將COCO數(shù)據(jù)放在何處并下載,例如:
cp scripts/get_coco_dataset.sh data cd data bash get_coco_dataset.sh現(xiàn)在您應(yīng)該擁有為Darknet生成的所有數(shù)據(jù)和標(biāo)簽。
修改COCO的cfg
現(xiàn)在去你的Darknet文件夾。我們得換cfg/coco.data指向數(shù)據(jù)的配置文件:
1 classes= 802 train = <path-to-coco>/trainvalno5k.txt3 valid = <path-to-coco>/5k.txt4 names = data/coco.names5 backup = backup您應(yīng)該將替換為放置coco數(shù)據(jù)的目錄。
您還應(yīng)該修改您的cfg模型以進(jìn)行培訓(xùn)而不是測試,cfg/yolo.cfg應(yīng)該是這樣的:
[net] # Testing # batch=1 # subdivisions=1 # Training batch=64 subdivisions=8 ....訓(xùn)練模型
現(xiàn)在我們可以訓(xùn)練了!運(yùn)行命令:
./darknet detector train cfg/coco.data cfg/yolov3.cfg darknet53.conv.74如果要使用多個GPU,請運(yùn)行:
./darknet detector train cfg/coco.data cfg/yolov3.cfg darknet53.conv.74 -gpus 0,1,2,3如果要從檢查點(diǎn)停止并重新啟動培訓(xùn):
./darknet detector train cfg/coco.data cfg/yolov3.cfg backup/yolov3.backup -gpus 0,1,2,3開源圖像數(shù)據(jù)集上的YOLOv3
wget https://pjreddie.com/media/files/yolov3-openimages.weights./darknet detector test cfg/openimages.data cfg/yolov3-openimages.cfg yolov3-openimages.weightsOld YOLO Site怎么了?
如果您使用的是YOLO版本2,您仍然可以在此處找到該網(wǎng)站:https://pjreddie.com/darknet/yolov2/
引用
如果你在工作中使用YOLOv3,請引用我們的論文!
@article{yolov3,title={YOLOv3: An Incremental Improvement},author={Redmon, Joseph and Farhadi, Ali},journal = {arXiv},year={2018} }總結(jié)
以上是生活随笔為你收集整理的YOLO_ Real-Time Object Detection 实时目标检测的全部內(nèi)容,希望文章能夠幫你解決所遇到的問題。

- 上一篇: 《408计算机网络》综合应用题
- 下一篇: 大话目标检测经典模型(RCNN、Fast